WEB?
WEB은 World Wide Web의 약자로 인터넷이라는 서비스 체계 위에서 동작하는 서비스 중에 하나입니다.
인터넷에 연결된 컴퓨터를 이용해 사람들과 정보를 공유할 수 있는 거미줄(Web)처럼 얼기설기 엮인 공간을 뜻하는 용어다.
WEB라는 서비스는 어떻게 보면 인터넷에서 동작하는 다른 전체를 합한 것보다 훨씬 더 많이 사용되고 가장 성공적인 서비스이기도 합니다. 그래서 대게 인터넷은 웹으로 보는 경향이 많다고 생각됩니다 하지만 WEB과 인터넷은 서로 다른 것입니다
인터넷이라는 것은 컴퓨터와 컴퓨터가 연결해주는 네트워크 체계입니다 이러한 네트워크 체계 위에서 동작하는 서비스가 WEB, FTP, EMAIL, 스트리밍, 웹캠, 온라인 게임 등등이며, 이러한 것들이 서로 같은 체계에서 돌아가는 서비스라고 할 수 있습니다.
서버와 클라이언트 관계
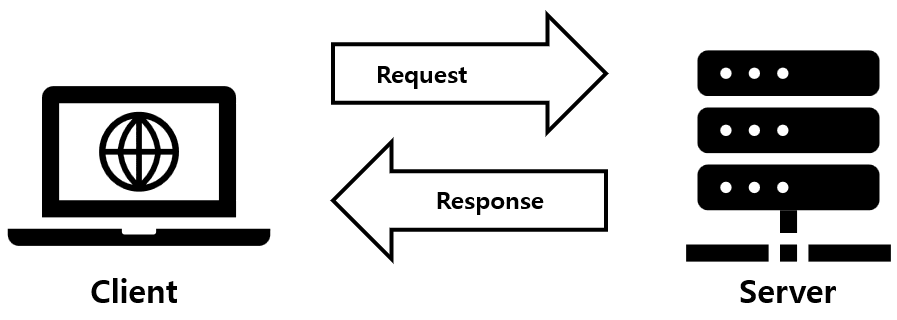
서버는 "서브" 정보를 제공한다는 의미로 서버이며, 정보를 제공하는 사업자가 사용하는 컴퓨터 또는 컴퓨터 위에 설치되어 있는 소프트웨어들을 서버라고 부릅니다.
클라이언트는 무언가를 요청하는 사람을 클라이언트라고 합니다.
즉 서비스 및 데이터를 요청하는 쪽이 클라이언트입니다.
표면적으로 웹브라우저인 크롬, 파이어폭스, 익스플로러를 웹 클라이언트라고 합니다
HTTP
HTTP는 인터넷 위에서 동작하는 서비스 중에서 하나인 WEB이라는 서비스를 이용하기 위해서 준수해야 되는 통신 규약을 HTTP라고 합니다.
즉, 클라이언트가 서버에게 요청할 때는 어떻게 요청해야 되고 또 그 요청에 대해서 서버가 응답할 때에는 어떻게 응답해야 되는가?라고 하는 것이 약속 규칙으로 미리 정해져 있습니다.
그 규칙에 따라서 먼저 요청하고 응답해야겠지만 서로 다른 컴퓨터들이 데이터를 주고받을 수 있습니다 바로 웹에 있어서 약속 체계를 HTTP라고 합니다.
WEB Server
HTTP를 다른 말로는 WEB 서버라고도 합니다 웹서버라는 것을 웹을 제공하는 서버라는 뜻이고 HTTP 서버라는 것을 HTTP라는 웹서비스를 사용할 수 있도록 도와주는 공통된 약속 규약을 사용하는 서버라는 뜻입니다 그래서 웹서버라고 부르고 HTTP 서버라고도 합니다 두 가지는 같은 의미로 사용됩니다.
Web Browser
HTML 문서와 그림, 멀티미디어 파일 등 WWW을 기반으로 한 인터넷의 콘텐츠를 검색 및 열람하기 위한 응용프로그램의 총칭.
HTML HyperText Mark-up Language
웹 페이지의 모습을 기술하기 위한 규약.
프로그래밍 언어가 아니라 마크업 언어다. 헷갈리지 않도록 하자. 웹사이트에서 흔히 볼 수 있는 htm이나 html 확장자가 바로 이 언어로 작성된 문서다.
마크업 언어(Markup Language)
문서가 화면에 표시되는 형식을 나타내거나 데이터의 논리적인 구조를 명시하기 위한 규칙들을 정의한 언어의 일종이다.
데이터를 기술한 언어라는 점에서 프로그래밍 언어와는 분명한 차이가 있다.
마크업 언어는 절차성을 가지는 일반적인 프로그래밍 언어와 달리 느슨한 튜링 완전히 아니다.
튜링 머신에서 튜링 완전하기 위해서는 조건 분기문을 가지고 있고 메모리의 임의의 값을 수정할 수 있어야 한다.
하지만 마크업 언어는 이러한 과정을 하지 못하기 때문에 튜링 완전하지 않으며 프로그래밍 언어의 정의에 부합하지 않는다.
월드 와이드 웹(World Wide Web, WWW, W3)
인터넷에 연결된 컴퓨터를 이용해 사람들과 정보를 공유할 수 있는 거미줄(Web)처럼 얼기설기 엮인 공간을 뜻하는 용어다.
HTTP 프로토콜을 기반으로 HTML로 작성된 하이퍼텍스트 페이지를 웹 브라우저라는 특정한 프로그램으로 읽을 수 있게 하도록 구성되어 있다.
프로그램
소프트웨어의 한 가지로, 어떤 문제를 해결하기 위하여 그 처리 방법과 순서를 기술하여 컴퓨터에 주어지는 일련의 명령문 집합체를 뜻한다. 쉽게 말해, 사용자의 명령에 반응하는 소프트웨어를 프로그램이라 한다.
일반적으론, 프로그램은 소프트웨어의 동의어로 취급되는데, 엄밀히 말해, 프로그램은 소프트웨어의 하위 집합이다.
최근에는 애플리케이션 또는 앱이라고 불리기도 한다.
입력 물(Input)에 대한 사용자의 명령(Instruction)에 따라 일련의 산출물(Output)을 제공하는 소프트웨어를 말한다.
통상적으로 프로그램은 소프트웨어의 동의어로 사용되나, 소프트웨어가 보다 큰 개념으로 프로그램을 포함하고 있다.
옛날에는 프로그램을 시스템 소프트웨어, 응용 소프트웨어, 유틸리티의 세 가지로 분류했다.
하지만 오늘날엔 유틸리티라는 개념이 점차 사라지며, 프로그램을 주로 시스템 소프트웨어, 응용 소프트웨어, 악성코드(멀웨어)로 분류한다.
애플리케이션
application software 혹은 application program의 준말.
응용 소프트웨어란 말이 바로 이 application software의 번역어로, 운영체제를 제외한 나머지 소프트웨어/프로그램을 말한다.
특정 목적을 위해 제작된 프로그램을 의미한다. 프로그램이란 거시적으로는 명령 코드의 집합체를 의미하고, 이를 세분화하면 크게 시스템 프로그램과 응용 프로그램으로 나뉜다. 시스템 프로그램은 운영체제를 의미하고 응용 프로그램이 바로 애플리케이션을 의미한다.
그렇다면 왜 하필 '응용' 프로그램일까? 답은 간단하다.
시스템 프로그램을 이용하고 응용해서 특정 기능만 하도록 새로 만들어낸 프로그램이니 응용 프로그램이라고 하는 것이다.
모바일에서의 인지도가 워낙 큰 탓에 대중의 인식은 '애플리케이션 = 스마트폰용 소프트웨어', '프로그램 = PC용 소프트웨어'로 고정되어 버렸다. 하지만 다시 말하지만 PC에 설치하는 프로그램들이나, 모바일에 까는 프로그램들이나 결국 똑같은 애플리케이션들이다.
다만 국내에서는 모바일의 차별을 위해 컴퓨터에 설치하는 응용 프로그램은 여전히 프로그램이라고 부르고, 모바일에 설치하는 응용 프로그램은 앱이라고 부르게 되었다, 정도로 이해하면 된다.
Software - 소프트웨어
응용 프로그램과 데이터처럼, 컴퓨터의 하드웨어 상에서 구동되거나 처리되는 무형물을 뭉뚱그려 지칭하는 말이다.
소프트웨어는 컴퓨터의 시스템을 구성하는 주요 요소 중 하나이다(컴퓨터 = 하드웨어 + 소프트웨어 + 펌웨어).
우리가 컴퓨터를 사용하는 목적은 소프트웨어를 이용하거나 처리하기 위함이며, 소프트웨어가 없는 컴퓨터(즉 하드웨어)는 그냥 빈 껍질이다. 그런 컴퓨터에 전원을 넣어봐야 아무 일도 일어나지 않는다.
간혹 소프트웨어의 반대말이 하드웨어라고 생각하는 이들이 있으나, 둘 다 컴퓨터 시스템을 구성하는 구성 요소이며 상호 보완적인 기능을 한다. 반대말이 아니다.
Hardware - 하드웨어
소프트웨어와 함께 컴퓨터를 구성하는 필수 요소 중 하나. 비유하자면 인간의 몸에 해당하는 부분이기 때문에 없어서는 안 되는 것이다. 기본적으로 입력장치, 출력장치, 연산장치, 기억장치, 제어장치로 나눌 수 있다.
전원장치와 연결장치를 추가하여 나누기도 한다.
HTTP
하이퍼텍스트를 빠르게 교환하기 위한 프로토콜의 일종으로 즉, HTTP는 서버와 클라이언트의 사이에서 어떻게 메시지를 교환할지를 정해놓은 규칙인 것이다. 80번 포트를 사용하며 HTTP의 구조는 요청(Request)과 응답(Response)으로 구성되어 있다.
예시를 들자면 '클라이언트가 웹 페이지에서 링크가 걸려있는 텍스트를 클릭(요청)하면 링크를 타고 새로운 페이지로 넘어간다(응답)'.
따라서 우리가 사용하는 웹 브라우저에서 인터넷 주소 맨 앞에 들어가는 http://는 바로 이 프로토콜을 사용해서 정보를 교환하겠다는 표시인 것이다.
Port - 포트
각 프로토콜의 데이터가 통하는 논리적 통로이다.
컴퓨터의 물리적 포트(랜선)에서 데이터가 통해오는 것처럼, 컴퓨터 안에서 각 프로토콜의 데이터가 컴퓨터 내부의 논리적 포트에 따라 흐른다.
HTTP는 요청(Request)과 응답(Response)으로 구성되어 있고, 클라이언트가 요청을 하면 서버가 응답을 하는 구조로 되어 있다.
HTTP는 FTP나 텔넷과는 다르게 비연 결식이다. FTP나 Telnet은 클라이언트가 서버에 정보를 요청해도 서버가 클라이언트와 연결을 끊지 않지만, HTTP는 클라이언트가 서버에 정보를 요청하면 응답 코드와 내용을 전송하고 클라이언트와 연결을 종료한다.
우리가 나무 위키에 접속을 했다고 가정하자. 접속하면 클라이언트는 GET명령을 나무 위키 서버에 전송한다. GET 요청을 받은 나무 위키는 응답 코드와 메시지를 전송하고 그것을 브라우저가 뿌려주는 것이다.
HTTP에서 지원하는 요청 메시지는 다음과 같다.
- GET: 클라이언트가 서버에게 URL에 해당하는 자료의 전송을 요청한다.
- HEAD: GET 요청으로 반환될 데이터 중 헤더 부분에 해당하는 데이터만 요청한다.
- POST: 클라이언트가 서버에서 처리할 수 있는 자료를 보낸다. 예를 들어, 게시판에 글을 쓸 때 클라이언트의 문서가 서버로 전송되어야 한다.
- PATCH: 클라이언트가 서버에게 지정한 URL의 데이터를 부분적으로 수정할 것을 요청한다.
- PUT: 클라이언트가 서버에게 지정한 URL에 지정한 데이터를 저장할 것을 요청한다.
- DELETE: 클라이언트가 서버에게 지정한 URL의 정보를 제거할 것을 요청한다.
- TRACE: 클라이언트가 서버에게 송신한 요청의 내용을 반환해 줄 것을 요청한다.
- CONNECT: 클라이언트가 특정 종류의 프록시 서버에게 연결을 요청한다.
- OPTIONS: 해당 URL에서 지원하는 요청 메시지의 목록을 요청한다.
GET / POST
http 프로토콜에서 데이터를 서버에 요청하는 방식으로 대표적인 것이 get과 post방식이다.
GET 방식은 주소에 데이터(data)를 추가하여 전달하는 방식입니다.
GET 방식의 HTTP 요청은 브라우저에 의해 캐시 되어(cached) 저장됩니다.
또한, GET 방식은 보통 쿼리 문자열(query string)에 포함되어 전송되므로, 길이의 제한이 있습니다.
따라서 보안상 취약점이 존재하므로, 중요한 데이터는 POST 방식을 사용하여 요청하는 것이 좋습니다.
POST 방식은 데이터(data)를 별도로 첨부하여 전달하는 방식입니다.
POST 방식의 HTTP 요청은 브라우저에 의해 캐시 되지 않으므로, 브라우저 히스토리에도 남지 않습니다.
또한, POST 방식의 HTTP 요청에 의한 데이터는 쿼리 문자열과는 별도로 전송됩니다.
따라서 데이터의 길이에 대한 제한도 없으며, GET 방식보다 보안성이 높습니다.
쿼리 스트링(Query String)
사용자가 입력 데이터를 전달하는 방법 중의 하나로, url 주소에 미리 협의된 데이터를 파라미터를 통해 넘기는 것을 말한다.
query parameters( 물음표 뒤에 = 로 연결된 key value pair 부분)을 url 뒤에 덧붙여서 추가적인 정보를 서버 측에 전달하는 것이다.
클라이언트가 어떤 특정 리소스에 접근하고 싶어 하는지 정보를 담는다.
형식
- 정해진 엔드포인트 주소 이후에?를 쓰는 것으로 쿼리 스트링이 시작함을 알린다
- parameter=value로 필요한 파라미터의 값을 적는다
- 파라미터가 여러 개일 경우 &를 붙여 여러 개의 파라미터를 넘길 수 있다.
엔드포인트주소/엔드포인트주소?파라미터=값&파라미터=값 - = 로 key와 value 가 구분된다.
JSON(JavaScript Object Notation)
원래는 자바스크립트 언어에서 객체 속성을 표현하기 위한 방법으로 사용하기 시작한 데이터 구조.
간결하고 쉽게 데이터를 나타내는 방법 중 하나(텍스트 형태로 데이터를 쉽고 간편하게 만들 수 있음)
JSON 객체
{ "Key" : Value }
중괄호로 시작해서 중괄호로 끝나고 그 안에 키와 벨류가 콜론으로 나뉘어 쌍을 이루어 들어간다.
추가하고 싶다면 , 컴마를 붙이고 추가하면 된다.
키 값은 문자열만 가능하고 벨류 값은 문자열, 숫자, 배열 등등 다양한 타입이 가능하다.
Dictionary와 비슷
JSON 배열
대괄호 [ 로 시작해서, 대괄호 ]로 끝나고, 사이에 원하는 json객체를 넣어주면 된다.
RESTful API
RESTful API라는 단어에서 사용되는 REST(REpresentational State Transfer)의 개념을 한 줄로 정의하자면 아래와 같이 정의할 수 있습니다.
HTTP 통신에서 어떤 자원에 대한 CRUD 요청을 Resource와 Method로 표현하여 특정한 형태로 전달하는 방식
즉, REST란 어떤 자원에 대해 CRUD(Create, Read, Update, Delete) 연산을 수행하기 위해 URI(Resource)로 요청을 보내는 것으로, Get, Post 등의 방식(Method)을 사용하여 요청을 보내며, 요청을 위한 자원은 특정한 형태(Representation of Resource)로 표현됩니다.
그리고 이러한 REST 기반의 API를 웹으로 구현한 것이 RESTful API입니다.
예를 들어, 우리는 게시글을 작성하기 위해 http://localhost:8080/board
라는 URI에 POST방식을 사용하여 JSON형태의 데이터를 전달할 수 있습니다.
위와 같이 CRUD 연산에 대한 요청을 할 때, 요청을 위한 Resource(자원, URI)와 이에 대한 Method(행위, POST)
그리고 Representation of Resource(자원의 형태, JSON)을 사용하면 표현이 명확해지므로 이를 REST라 하며,
이러한 규칙을 지켜서 설계된 API를 Rest API 또는 Restful 한 API라고 합니다.
그리고 위에서 살짝 언급하였듯이, 이러한 Rest API는 Resource(자원), Method(행위), Representation of Resource(자원의 형태)로 구성됩니다.
RESTful API의 구성요소
Resource 자원
서버는 유니크한 ID를 가지는 리소스 URI를 가지고 있으며, 클라이언트는 이러한 리소스에 요청을 보낸다.
Method 메서드
서버에 요청을 보내기 위한 방식 GET, POST, PUT, DELETE가 있다.
CRUD 연산 중에서 처리를 위한 연산에 맞는 메서드를 사용해 서버에 요청을 보낸다.
Representation of Resource 자원의 표현
클라이언트와 서버가 데이터를 주고받는 형태로 json, xml 등이 있다.
URI과 URL의 차이점은?
URL은 Uniform Resource Locator로 인터넷 상 자원의 위치를 의미합니다.
자원의 위치라는 것은 결국 어떤 파일의 위치를 의미합니다.
반면에 URI는 Uniform Resource Identifier로 인터넷 상의 자원을 식별하기 위한 문자열의 구성으로, URI는 > URL을 포함하게 됩니다. 그러므로 URI가 보다 포괄적인 범위라고 할 수 있습니다.
REST의 특징
1. Uniform Interface(일관된 인터페이스)
Uniform Interface란, Resource(URI)에 대한 요청을 통일되고, 한정적으로 수행하는 아키텍처 스타일을 의미합니다. 이것은 요청을 하는 Client가 플랫폼(Android, Ios, Jsp 등)에 무관하며, 특정 언어나 기술에 종속받지 않는 특징을 의미합니다. 이러한 특징 덕분에 Rest API는 HTTP를 사용하는 모든 플랫폼에서 요청 가능하며, Loosely Coupling(느슨한 결함) 형태를 갖게 되었습니다.
2. Stateless(무상태성)
서버는 각각의 요청을 별개의 것으로 인식하고 처리해야 하며, 이전 요청이 다음 요청에 연관되어서는 안 됩니다. 그래서 Rest API는 세션정보나 쿠키 정보를 활용하여 작업을 위한 상태 정보를 저장 및 관리하지 않습니다. 이러한 무상태성 때문에 Rest API는 서비스의 자유도가 높으며, 서버에서 불필요한 정보를 관리하지 않으므로 구현이 단순합니다. 이러한 무상태성은 서버의 처리방식에 일관성을 부여하고, 서버의 부담을 줄이기 위함입니다.
3. Cacheable(캐시 가능)
Rest API는 결국 HTTP라는 기존의 웹 표준을 그대로 사용하기 때문에, 웹의 기존 인프라를 그대로 활용할 수 있습니다. 그러므로 Rest API에서도 캐싱 기능을 적용할 수 있는데, HTTP 프로토콜 표준에서 사용하는 Last-Modified Tag 또는 E-Tag를 이용하여 캐싱을 구현할 수 있고, 이것은 대량의 요청을 효율적으로 처리할 수 있게 도와줍니다.
4. Client-Server Architecture (서버-클라이언트 구조)
Rest API에서 자원을 가지고 있는 쪽이 서버, 자원을 요청하는 쪽이 클라이언트에 해당합니다. 서버는 API를 제공하며, 클라이언트는 사용자 인증, Context(세션, 로그인 정보) 등을 직접 관리하는 등 역할을 확실히 구분시킴으로써 서로 간의 의존성을 줄입니다.
5. Self-Descriptiveness(자체 표현)
Rest API는 요청 메시지만 보고도 이를 쉽게 이해할 수 있는 자체 표현 구조로 되어있습니다. 아래와 같은 JSON 형태의 Rest 메시지는 http://localhost:8080/board로 게시글의 제목, 내용을 전달하고 있음을 손쉽게 이해할 수 있습니다. 또한 board라는 데이터를 추가(POST)하는 요청임을 파악할 수 있습니다.
HTTP POST , http://localhost:8080/board
{
"board": {
"title":"제목",
"content":"내용"
}
}
6. Layered System(계층 구조)
Rest API의 서버는 다중 계층으로 구성될 수 있으며 보안, 로드 밸런싱, 암호화 등을 위한 계층을 추가하여 구조를 변경할 수 있습니다. 또한 Proxy, Gateway와 같은 네트워크 기반의 중간 매체를 사용할 수 있게 해 줍니다. 하지만 클라이언트는 서버와 직접 통신하는지, 중간 서버와 통신하는지 알 수 없습니다.
출처: https://mangkyu.tistory.com/46 [MangKyu's Diary]
REST API 사용 경험
앱 프로젝트를 수행할 당시 서버의 API 문서를 기반으로 필요한 데이터들을 얻기 위해 REST API 요청을 보냈습니다.
JSON 값을 받아와 파싱 해서 앱을 만드는 데 이를 사용했습니다.
서버 개발을 할 당시에는 네이버 API(또는 공공 API)를 이용해 ~정보를 받아온 경험이 있습니다.
안드로이드의 서버 통신
안드로이드는 서버와 통신하기 위한 방법으로 HTTP 통신과 Socket 통신이 있다.
HTTP 통신은 URL 접속을 통해 데이터를 읽어오는 방법이다.
일반적으로 DB에 있는 데이터를 가져오기 위해 서버 통신을 한다.
하지만 안드로이드의 특성상 외부 DB에 직접 접근할 수 없어 중간 매체로 웹을 사용한다.
자신의 DB와 웹에서 데이터를 가져오기 위해서는 호스팅이나 개인 서버를 구축한 후, 만든 웹 문서가 포함된 로컬 호스트 주소에 접속하여 데이터를 얻어와야 한다.
Retrofit2 / GSON
Retrofit2은 안드로이드와 자바에서 쉽게 Restful 한 통신을 할 수 있게 해주는 라이브러리이다.
사용 방법이 용이하고 속도도 다른 라이브러리에 비해 빨라서 많이 사용하는 라이브러리이다.
https://sys09270883.github.io/app/46/
응답 코드
자세한 내용은 HTTP/응답 코드 문서
HTTP VS HTTPS
HTTP는 평문 데이터를 전송하는 프로토콜이기 때문에, HTTP로 비밀번호나 주민번호 등을 주고받으면 제삼자에 의해 조회될 수 있습니다. 이러한 문제를 해결하기 위해 HTTP에 암호화가 추가된 프로토콜이 HTTPS입니다.
HTTPS는 자신의 공개키를 갖는 인증서를 발급하여 보내는 메시지를 공개키로 암호화하도록 하고 있습니다.
공개키로 암호화된 메시지는 개인키를 가지고 있어야만 복호화가 가능하기 때문에, 기업을 제외한 누구도 원본 데이터를 얻을 수 없습니다.
HTTPS
TLS를 사용해 암호화된 연결을 하는 HTTP를 HTTPS(HTTP Secure)라고 하며, 당연히 웹사이트 주소 역시 http://가 아닌 https://로 시작된다. 기본 포트는 80번이 아닌 443번을 쓴다.
흔히 TLS와 HTTPS를 혼동하는 경우가 많은데, 둘은 유사하긴 하지만 엄연히 다른 개념임을 알아두자. TLS는 다양한 종류의 보안 통신을 하기 위한 프로토콜이며, HTTPS는 TLS 위에 HTTP 프로토콜을 얹어 보안된 HTTP 통신을 하는 프로토콜이다. 다시 말해 TLS는 HTTP뿐만이 아니라 FTP, SMTP와 같은 여타 프로토콜에도 적용할 수 있으며, HTTPS는 TLS와 HTTP가 조합된 프로토콜만을 가리킨다.
Transport Layer Security
인터넷에서의 정보를 암호화해서 송수신하는 프로토콜.
넷스케이프 커뮤니케이션스사가 개발한 SSL(Secure Sockets Layer)에 기반한 기술로, 국제 인터넷 표준화 기구에서 표준으로 인정받은 프로토콜이다. 표준에 명시된 정식 명칭은 TLS지만 아직도 SSL이라는 용어가 많이 사용되고 있다.





출처 : https://blog.naver.com/skinfosec2000/222135874222
DNS(Domain Name System)
- Host : 인터넷에 연결된 컴퓨터 한 대 한대
- IP Address : host끼리 통신을 하기 위해 필요한 주소
- IP 주소를 기억하는 것이 어렵기 때문에 DNS(Domain Name System)이 나왔습니다
- DNS Server : 수많은 IP 주소와 도메인이 저장되어 있습니다
- 웹에서 www.naver.com을 입력하면 DNS Server에 www.naver.com의 IP 주소를 알려준 후, 그 IP 주소를 토대로 접속하는 것입니다
IP 주소와 Hosts의 개념
2대의 컴퓨터가 인터넷 통신을 위해 반드시 필요한 것은 IP 주소입니다.
비단 컴퓨터뿐만이 아닌, 인터넷이 연결된 것은 Host라고 부릅니다.
단, 모든 IP 주소를 기억하는 일은 너무 어렵습니다. 이것을 해결하기 위해 운영체제마다 hosts라는 파일이 존재합니다.
이 파일에 IP와 도메인 이름을 저장해두면, 도메인 이름을 통해 다른 host에 접근할 수 있습니다(DNS을 사용하지 않고도!)
DNS Server
DNS Server는 IP 주소와 Domain 이름을 기억하는 기능과 Client가 이름을 물어보면 IP를 알려주는 기능을 갖고 있습니다.
수천 대의 서버가 같이 협력하고 있습니다.

맨 뒤에는 사실 .이 생략되어 있습니다.
각각의 부분들은 부분들을 담당하는 독자적인 Server Computer가 존재합니다.
Root는 Top-level을 담당하는 Server의 목록과 IP를 알고 있으며, Top-level은 Second-level, Second-level은 sub의 목록과 IP를 알고 있습니다(상위 목록이 직속 하위 목록을 알고 있음)
최초 root 네임서버의 IP 주소에게 blog.example.com을 물어보면 .com을 담당하는 Top-level을 알려주고, Top-level은 example.com을 담당하는 Second-level을 알려주고, Second-level은 blog.example.com 담당하는 sub DNS Server에게 물어보고, sub가 해당 IP 주소를 알려줍니다! 계층적인 구조를 가지고 있습니다.
1. 쿠키(cookie)
브라우저를 사용하는 환경 (로컬 컴퓨터)에 서버에서 받은 데이터를 저장한 파일
- 로그인 정보 같이 유저가 굳이 다시 서버에 다시 요청하기에는 비효율적인 정보를 로컬에 저장해둠으로써 생산성을 높이는 것이 목적!
- 로그인 정보 등 사용자의 정보가 저장되는 경우가 많아 보안 문제를 잘 살펴야 함.
- 다시 서버에 request 할 필요가 없기 때문에 속도가 빠름
- 사용 예 : 자동 로그인, 오늘 그만 보기 팝업창 등
2. 세션(session)
서버에서 유저의 인증 상태 (로그인 여부 등)을 임시로 저장한 파일
- 쿠키와 같이 임시로 유저의 정보를 저장해둠으로써 생산성을 높이는 것이 목적!
- 서버에 저장해두기 때문에 쿠키보다 보안이 우수함.
- 서버에 저장되어있어서 쿠키보다 다소 느리고 유저 정보가 많으면 메모리 과부하가 생길 수 있음.
- 서버에서 관리하기 때문에 로그관리 용이함.
- 사용 예 : 로그인 한 정보들
3. 쿠키와 세션
- 공통점 : 데이터를 임시로 계속 저장해두는 역할.
- 차이점 : 쿠키는 사용자에게 저장되고 세션은 서버에 저장됨.
웹 개발 시 어떤 정보를 쿠키로 저장할지, 세션으로 저장할지 적절히 판단하는 것이 중요하다.
4. 캐시(cache)
브라우저를 사용하는 환경(로컬 컴퓨터)에 서버에서 받은 데이터를 저장한 파일 (쿠키와 동일)
- 이미지같이 재사용될 것 같거나 용량이 큰 리소스를 임시로 저장해두어서 렌더링 속도를 높이는 것이 목적!
- 쿠키와는 비슷하지만 목적성에 차이가 있다
출처 : https://velog.io/@kimtaeeeny/쿠키cookie-세션session-과-캐시cache-FE-study9
공인 IP와 사설 IP 차이
- 공인 IP
- 전 세계에서 유일한 IP로 ISP(인터넷 서비스 공급자)가 제공하는 IP주소
- 외부에 공개되어 있기 때문에 인터넷에 연결된 다른 장비로부터 접근이 가능하다.
- 그에 따라 방화벽 등과 같은 보안 설정을 해주어야 한다.
- 사설 IP
- 어떤 네트워크 안에서 사용되는 IP주소
- IPV4의 부족으로 인해 모든 네트워크가 공인 IP를 사용하는 것이 불가능하기 때문에, 네트워크 안에서 라우터를 통해 할당받는 가상의 주소이다.
- 별도의 설정 없이는 외부에서 접근이 불가능하다.
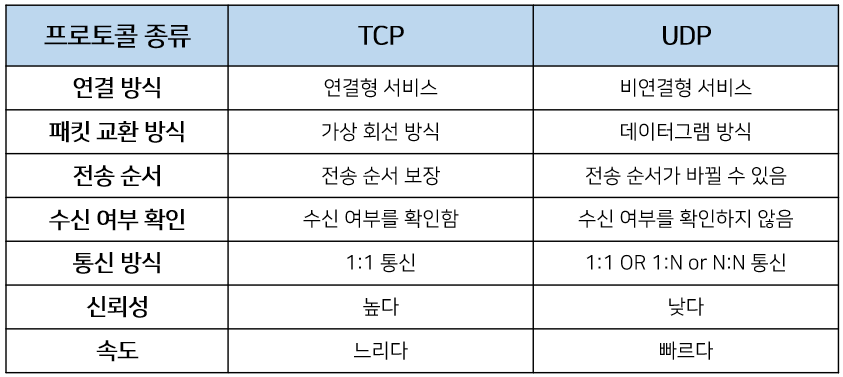
TCP와 UDP 차이
TCP는 연결형 서비스로 3-way handshaking 과정을 통해 연결을 설정합니다.
그렇기 때문에 높은 신뢰성을 보장하지만 속도가 비교적 느리다는 단점이 있습니다.
UDP는 비연결형 서비스로 3-way handshaking을 사용하지 않기 때문에 신뢰성이 떨어지는 단점이 있습니다.
하지만 수신 여부를 확인하지 않기 때문에 속도가 빠릅니다.
TCP는 신뢰성이 중요한 파일 교환과 같은 경우에 쓰이고 UDP는 실시간성이 중요한 스트리밍에 자주 사용됩니다.
출처: https://mangkyu.tistory.com/91 [MangKyu's Diary]
TCP 3-way Handshake?
통신을 하는 장치 간 서로 연결이 잘 되어있는지 확인하는 과정, 방법이다.
TCP는 장치들 사이에 논리적인 접속을 성공적으로 성립(establish) 하기 위하여 three-way handshake를 사용한다.
TCP 3 Way Handshake는 TCP/IP 프로토콜을 이용해서 통신을 하는 응용프로그램이 데이터를 전송하기 전에
먼저 정확한 전송을 보장하기 위해 상대방 컴퓨터와 사전에 세션을 수립하는 과정을 의미한다.
Client > Server : TCP SYN
Server > Client : TCP SYN ACK
Client > Server : TCP ACK
여기서 SYN은 'synchronize sequence numbers', 그리고 ACK는'acknowledgment'의 약자이다.
이러한 절차는 TCP 접속을 성공적으로 성립하기 위하여 반드시 필요하다.
* TCP의 3-way Handshaking 역할
• 양쪽 모두 데이터를 전송할 준비가 되었다는 것을 보장하고, 실제로 데이터 전달이 시작하기 전에 한쪽이 다른 쪽이 준비되었다는 것을 알 수 있도록 한다.
• 양쪽 모두 상대편에 대한 초기 순차 일련변호를 얻을 수 있도록 한다.

* TCP의 3-way Handshaking 과정
[STEP 1]
클라이언트는 서버에 접속을 요청하는 SYN 패킷을 보낸다.
이때 클라이언트는 SYN을 보내고 SYN/ACK 응답을 기다리는 SYN_SENT 상태가 되는 것이다.
[STEP 2]
서버는 SYN요청을 받고 A클라이언트에게 요청을 수락한다는 ACK와 SYN flag 가 설정된 패킷을 발송하고,
클라이언트가 다시 ACK으로 응답하기를 기다린다. 이때 B서버는 SYN_RECEIVED 상태가 된다.
[STEP 3]
클라이언트는 서버에게 ACK을 보내고, 이후부터는 연결이 이루어지고 실제 데이터가 오가게 되는 것이다.
이때의 서버 상태가 ESTABLISHED이다.
위와 같은 방식으로 통신하는 것이 신뢰성 있는 연결을 맺어 준다는 TCP의 3 Way handshake 방식이다.
출처: https://mindnet.tistory.com/entry/네트워크-쉽게-이해하기-22편-TCP-3-WayHandshake-4-WayHandshake [Mind Net]
SYN Flooding
이 3 way handshaking의 취약점을 이용해 서버를 공격하는 방법이 있는데 이를 SYN Flooding이라 한다
3 way handshaking 과정 중 서버는 2단계에서 (클라이언트로부터 요청을 받고 응답을 하고 난 후 다시 클라이언트의 응답을 기다리는 상태) 이 연결을 메모리 공간인 백로그 큐(Backlog Queue)에 저장을 하고 클라이언트의 응답 즉 3단계를 기다리게 되고 일정 시간 (default로 UNIX/LINUX : 60초 , Windows : 256초 , Apache : 300 초이며 수정 가능) 동안 응답이 안 오면 연결을 초기화한다.
바로 이 점을 이용한 공격법이다.
악의적인 공격자가 실제로 존재하지 않는 클라이언트 IP로 응답이 없는 연결을 초기화하기 전에 또 새로운 연결 즉 1단계 요청만 무수히 많이 보내어 백로그 큐를 포화 상태로 만들어 다른 사용자로부터 더 이상에 연결 요청을 못 받게 하는 공격 방법이다.
대응책으로는 연결 타이머 시간을 짧게 하거나 백로그 큐 사이즈를 늘리는 법, 정해진 시간 동안 들어오는 연결 요구의 수를 제한하는 법, 쿠키(cookie)라는 것을 이용해서 전체 연결이 설정되기 전까지는 자원의 할당을 연기하는 법이 있다.
4 way hand shaking
송신 측 수신 측이 세션을 종료할 때 사용하는 방법
FIN
TCP 흐름 제어 / 혼잡 제어
흐름 제어 (Flow Control)
송신 측과 수신 측의 데이터 처리 속도 차이를 해결하기 위한 기법
수신 측이 송신 측보다 데이터 처리 속도가 빠르면 문제없지만, 송신 측의 속도가 빠를 경우 문제가 생긴다.
수신 측에서 제한된 저장 용량을 초과한 이후에 도착하는 데이터는 손실될 수 있으며, 만약 손실된다면 불필요하게 응답과 데이터 전송이 송/수신 측 간에 빈번히 발생한다.
이러한 위험을 줄이기 위해 송신 측의 데이터 전송량을 수신 측에 따라 조절해야 한다.
Stop and Wait
매번 전송한 패킷에 대해 확인 응답을 받아야만 그다음 패킷을 전송하는 방법
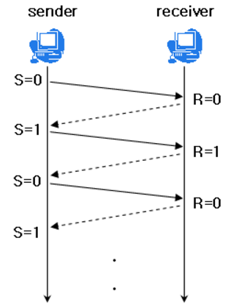
Sliding Window (Go Back N ARQ)
수신 측에서 설정한 윈도우 크기만큼 송신 측에서 확인 응답 없이 세그먼트를 전송할 수 있게 하여 데이터 흐름을 동적으로 조절하는 제어기법
먼저 윈도우에 포함되는 모든 패킷을 전송하고, 그 패킷들의 전달이 확인되는 대로 이 윈도우를 옆으로 옮김으로써 그다음 패킷들을 전송
혼잡 제어 (Congestion Control)
송신 측의 데이터 전달과 네트워크의 데이터 처리 속도 차이를 해결하기 위한 기법
1. AIMD(Additive Increase / Multiplicative Decrease) 합 증가 / 곱 감소
처음에 패킷을 하나씩 보내고 이것이 문제없이 도착하면 window 크기(단위 시간 내에 보내는 패킷의 수)를 1씩 증가시켜가며 전송하는 방법.
패킷 전송에 실패하거나 일정 시간을 넘으면 패킷의 보내는 속도를 절반으로 줄인다.
2. Slow Start (느린 시작)
Slow Start 방식은 AIMD와 마찬가지로 패킷을 하나씩 보내면서 시작하고, 패킷이 문제없이 도착하면 각각의 ACK 패킷마다 window size를 1씩 늘려준다. 즉, 한 주기가 지나면 window size가 2배로 된다.
대신에 혼잡 현상이 발생하면 window size를 1로 떨어뜨리게 된다.
3. Fast Retransmit (빠른 재전송)
빠른 재전송은 TCP의 혼잡 조절에 추가된 정책이다.
패킷을 받는 쪽에서 먼저 도착해야 할 패킷이 도착하지 않고 다음 패킷이 도착한 경우에도 ACK 패킷을 보내게 된다.
단, 순서대로 잘 도착한 마지막 패킷의 다음 패킷의 순번을 ACK 패킷에 실어서 보내게 되므로, 중간에 하나가 손실되게 되면 송신 측에서는 순번이 중복된 ACK 패킷을 받게 된다. 이것을 감지하는 순간 문제가 되는 순번의 패킷을 재전송해줄 수 있다.
중복된 순번의 패킷을 3개 받으면 재전송을 하게 된다. 약간 혼잡한 상황이 일어난 것이므로 혼잡을 감지하고 window size를 줄이게 된다.
4. Fast Recovery (빠른 회복)
혼잡한 상태가 되면 window size를 1로 줄이지 않고 반으로 줄이고 선형 증가시키는 방법이다.
이 정책까지 적용하면 혼잡 상황을 한번 겪고 나서부터는 순수한 AIMD 방식으로 동작하게 된다.
OSI 7 계층
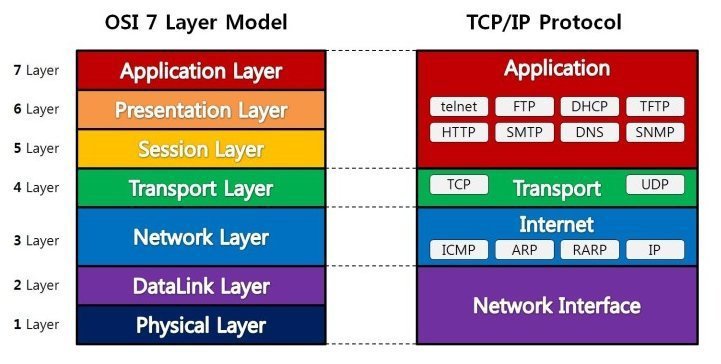
- 7 계층(응용 계층): 사용자와 직접 상호작용하는 응용 프로그램들이 포함된 계층
- 6 계층(표현 계층): 데이터의 형식(Format)을 정의하는 계층
- 5 계층(세션 계층): 컴퓨터끼리 통신을 하기 위해 세션을 만드는 계층
- 4 계층(전송 계층): 최종 수신 프로세스로 데이터의 전송을 담당하는 계층
- 3 계층(네트워크 계층): 패킷을 목적지까지 가장 빠른 길로 전송하기 위한 계층
- 2 계층(데이터링크 계층): 데이터의 물리적인 전송과 에러 검출, 흐름 제어를 담당하는 계층
- 1 계층(물리 계층): 데이터를 전기 신호로 바꾸어주는 계층
출처: https://mangkyu.tistory.com/91 [MangKyu's Diary]
OSI 참조 모델
- 다른 시스템 간의 원활한 통신을 위해 ISO에서 제안한 통신 규약
- 1~3 하위 계층 / 4~7 상위 계층
- 물리 - 데이터링크 - 네트워크 - 전송 - 세션 - 표현 - 응용
* 물리 계층 - 비트
전송에 필요한 두 장치 간의 실제 접속과 절단 등 기계, 전기, 기능, 절차적 특성에 대한 규칙 정의
물리적 전송 매체와 전송신호 방식 정의
리피터, 허브
데이터를 전기신호로 바꾸어주는 계층으로 이 과정에서 리피터와 허브가 사용된다.
허브는 한 사무실, 가까운 거리의 컴퓨터들을 연결하는 장치로, 각각의 회선을 통합하여 관리한다.
리피터는 거리가 증가할수록 감쇠하는 디지털 신호의 장거리 전송을 위해 수신한 신호를 재생시키거나 출력 전압을 높여 전송하는 장치
* 데이터 링크 계층 - 프레임(맥 주소를 기반으로 보냄)
물리계층에서의 데이터에 흐름 제어(속도 차이 해결), 오류제어, 순서 제어를 통해 신뢰할 수 있는 링크로 변환하는 계층
관련 장비로 랜카드, 브리지, 스위치가 있다.
랜카드 - 컴퓨터를 네트워크에 연결하여 통신하기 위해 사용하는 하드웨어 장치
브리지 - 랜과 랜 연결, 랜 안에서의 컴퓨터 그룹 연결을 하는 장치(네트워크를 분산 구성 -> 보안성 높임, 수많은 단말기들에 발생하는 트래픽 병목 현상을 줄일 수 있음)
스위치 - 랜과 랜 연결해 더 큰 랜을 만드는 장치, 하드웨어 기반으로 전송속도 빠름, 수많은 포트를 제공하고 포트마다 다른 전송 속도 지원
* 네트워크 계층 - 패킷
송신 측에서 수신 측 까지 패킷을 안전하게 전달하기 위한 계층으로 라우팅을 담당
라우팅이란 알고리즘을 통해 목적지까지 데이터를 전송하기 위한 최적의 경로를 설정하고 패킷을 교환하는 것을 말한다.
최종 목적지 노드까지 가기 위해선 노드에 대한 논리적 주소인 IP주소가 필요하다.
데이터 링크 계층이 같은 네트워크 상에서의 패킷 전달을 책임진다면, 네트워크 계층은 최종 목적지까지의 패킷 전달을 책임지는 것
라우터 - 랜과 랜 연결 기능에 데이터 전송의 최적 경로를 선택하는 라우팅 기능이 추가된 장치(랜 웬도 가능)
* 전송계층 - 세그먼트
종단 시스템(End to End) 간의 신뢰성 있는 데이터 전송을 담당. (연결, 오류, 흐름, 혼잡 제어)
종단 간 전송이랑 송신 컴퓨터에서 수식 컴퓨터의 응용프로그램으로의 전달을 의미한다.
목적지 프로세스를 찾아가기 위해 프로세스를 식별하기 위한 논리적 주소 Port주소가 필요하다.
하위 3 상위 3의 인터페이스 담당
게이트웨이 - OSI전 계층의 프로토콜 구조가 다른 네트워크를 연결하는 장치
랜에서 다른 네트워크에게 데이터를 보내거나 다른 네트워크로부터 데이터를 받아들이는 출입구 역할
L4 스위치 - 로드밸런서(특정 서버에만 부하가 발생하지 않도록 트래픽을 분산시켜주는 장비)가 달림
IP, TCP/UDP 기반
* 세션 계층 - 메시지
세션 - 두 이용자 사이의 연결을 의미
세션의 생성, 관리, 종료를 담당하는 계층
대화 제어를 담당하며 송수신 대화 동기(데이터 회복)를 위해 동기점을 두어 상태를 체크한다.
* 표현 계층
송수신자가 공통으로 이해할 수 있도록 데이터 표현 방식을 변환하는 기능 담당
코드 변환, 데이터 암호화, 데이터 압축, 구문 검색, 문맥 관리, 포맷 변환 등
* 응용계층
사용자(응용프로그램)가 네트워크에 접근할 수 있도록 인터페이스를 담당하는 계층
가상 터미널, 파일 전송, 응용 프로세스 간 정보 교환 등의 서비스 제공
출처 : https://liveyourit.tistory.com/186
프로토콜
서로 다른 기기들 간의 데이터 교환을 원활하게 수행할 수 있도록 표준화시켜놓은 통신 규약
TCP(Transmission Control Protocol) / IP(Internet Protocol)
서로 다른 기종의 컴퓨터들이 데이터를 주고받을 수 있도록 하는 표준 프로토콜
* TCP
전송 계층에 해당
신뢰성 있는 연결형 서비스 제공(연결형이라는 것은 논리적으로 연결 후 데이터 전송, 가상 회선 방식)
순서, 오류, 흐름 제어 기능을 제공
* IP
네트워크 계층에 해당
데이터 그램을 기반으로 하는 비연결형 서비스 제공
패킷의 분해/조립, 주소 지정, 경로 선택 기능 제공
ARP - 네트워크 계층에서 사용하는 주소 결정 프로토콜
호스트의 IP 주소를 네트워크 접속 장치의 물리적 주소(Mac 주소 - 랜 카드 제작사에서 랜 카드에 부여한 고유 번호)로 바꿈
RARP
ARP 반대 (Mac -> IP 주소)
블록체인
누구나 열람할 수 있는 디지털 장부에
거래 내역을 투명하게 기록하고,
여러 대의 컴퓨터에 이를 복제해 저장하는 분산형 데이터 저장기술
'면접' 카테고리의 다른 글
| [직무 면접 대비] SW 직무 면접 예상 면접 질문 (0) | 2021.10.20 |
|---|---|
| [직무 면접 대비] 운영체제 면접 예상 질문 (1) | 2021.05.20 |
| [인성 면접] 인성 면접 예상 질문 (0) | 2021.05.19 |
| [직무 면접 대비] 자료구조 예상 면접 질문 (0) | 2021.05.19 |
| [직무 면접 대비] JAVA 면접 예상 질문 및 답변 (0) | 2021.05.18 |

댓글