1. 컴퓨터 시스템 소개
운영체제를 쉽게 학습하려면 먼저 운영체제와 가장 밀접하게 관련 있는 프로세서를 중심으로 메모리, 주변장치와 같은 하드웨어를 살펴보는 것이 좋다.
그런 다음, 컴퓨터 시스템의 동작과 관련된 명령어 구성과 실행 과정, 입출력과 관련된 인터럽트의 개념을 이해해야 한다.
이런 개념들은 운영체제와 밀접한 관련이 있어서 운영체제를 학습하기 전에 기본으로 알아야 할 내용이기도 하다.
그래서 먼저 컴퓨터 시스템이 무엇인지 알아보자. (이미 숙지하고 있다면 바로 2. 운영체제부터 학습)
1) 컴퓨터 시스템 구성요소
* 컴퓨터 시스템은 데이터를 처리하는 물리적인 기계장치인 하드웨어 + 특별한 작업을 지시하려고 명령어로 작성한 프로그램인 소프트웨어로 구성된다.
* 운영체제는 컴퓨터 하드웨어와 사용자 사이에 위치해 하드웨어와 소프트웨어 자원을 관리하는 프로그램이다.
컴퓨터 하드웨어는 보통 프로세서, 버스, 메모리 등 다양한 주변장치로 구성된다.
각 장치가 세부적으로 어떻게 구성되고 동작하는지를 이해하면 운영체제가 자원을 어떻게 관리하는지 원리를 쉽게 이해할 수 있다.
아래 그림 1-1과 같이 하드웨어 구성요소를 하나씩 살펴보자.
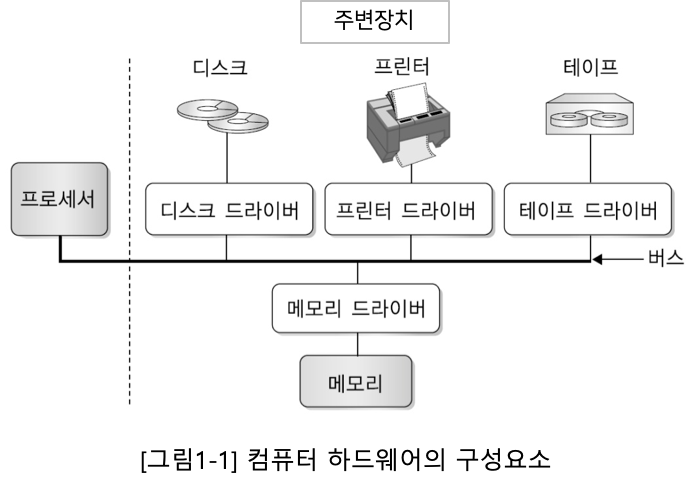
1-1) 프로세서 (CPU, Central Processing Unit, 중앙처리장치)
컴퓨터 각 부분의 동작 제어, 연산 수행
레지스터, 산술 논리 연산장치, 제어장치, 등으로 구성
(ex. 컴퓨터는 주기억장치를 제외한 레지스터, 산술 논리 연산장치, 제어장치를 칩 하나로 구성한 마이크로프로세서를 이용한다.)

1-2) 버스
프로세서를 비롯한 각 장치 또는 서브 시스템을 서로 연결하여 정보(데이터)를 주고받을 수 있게 해주는 통로
컴퓨터 내부의 다양한 신호(ex. 데이터 입출력 신호, 프로세서 상태 신호, 인터럽트 요구와 허가 신호, Clock 신호 등)는 버스를 통해 전달된다.
자세히 보려면 더보기 클릭
1. 위치에 따른 분류
내부 버스
-
프로세서 내부에서 레지스터, 연산장치, 메모리와의 인터페이스 등을 연결
-
시스템 버스 인터페이스 회로를 통해 외부 버스와 연결
외부 버스
-
프로세서와 메모리, 입출력 장치를 연결
-
시스템 버스라고도 하며 독립된 기능을 갖는 장치로 각 시스템 버스는 버스 제어기라고 불리는 제어회로를 갖고 있음
메모리 버스
-
프로세서와 메모리 또는 캐시 메모리를 연결해 데이터를 교환
-
백사이드 버스 : 프로세서와 캐시 메모리 간의 데이터 전송 / 속도 매우 빠름
-
프런트 사이드 버스 : 프로세서와 메모리 간의 데이터 전송 / 속도 느림
주변 버스 : 입출력 버스라고도 하며 프로세서와 주변장치를 연결해 데이터 전송
2. 기능에 따른 분류
-
데이터 버스
-
데이터, 명령어 등의 정보를 교환하는 전송로
-
양방향 버스(ex. 프로세서 -> 메모리, 입출력 장치로 데이터 출력 / 메모리, 입출력 장치 -> 프로세서로 데이터 입력)
-
신호선의 수가 해당 프로세서의 워드 길이와 같으므로 프로세서 성능을 결정하는 요소가 됨
-
-
주소 버스
-
하나의 시스템 장치에서 다른 장치로 주소 정보를 전송하는데 사용
-
신호(주소) 선의 수에 따라 최대 사용 가능한 메모리 용량이나 입출력 장치 수를 결정
-
-
제어 버스
-
프로세서가 저장장치와 입출력 장치에 데이터를 전송할 때, 현재 수행 중인 작업 종류나 상태를 다른 장치에 알릴 때 이용하는 단방향 버스
-

1-3) 레지스터
프로세서에 위치한 고속 메모리
프로세서가 바로 사용할 수 있는 데이터를 담는다.
자세히 보려면 더보기 클릭
- 특수한 값 하나를 저장하는 기억 공간으로 사용되며, 연산을 처리하다가 중간값을 저장하기도 한다.
- 컴퓨터 구조에 따라 레지스터의 크기, 종류가 다양하다.
1. 용도에 따라 분류
전용 레지스터
범용 레지스터
2. 저장되는 정보의 종류에 따라 분류
상태 레지스터
데이터 레지스터
- 함수 연산에 필요한 데이터를 저장
- 수치, 문자 등을 저장하므로 산술이나 논리연산에 이용되며, 연산 결과로 플래그 값을 저장
주소 레지스터
- 주소나 유효 주소를 계산하는데 필요한 주소의 일부분을 저장
- 주소 레지스터에 저장된 값(수치 데이터)을 이용해 산술 연산을 할 수 있다.
- 주소 레지스터 종류 :
-
기준 주소 레지스터
-
프로그램 실행 시 사용하는 기준 주소값을 저장한다.
-
기준 주소는 프로그램 하나나 일부처럼 서로 관련 있는 정보를 저장하며, 연속된 저장 공간을 지정하는데 참조할 수 있는 주소다.
-
따라서 기준 주소 레지스터는 페이지나 세그먼트처럼 블록화 된 정보에 접근하는 데 사용된다.
-
-
인덱스 레지스터
-
유효 주소를 계산하는 데 사용되는 주소 정보를 저장한다.
-
유효주소는 컴퓨터가 기계어 명령을 수행할 때 주소 연산 끝에 최종적으로 피연 사자가 있는 곳을 가리키는 주소
-
즉, 기준 주소로부터 거리로 주소를 나타낸다면 기준 주소에 거리값을 더하여 나온 주소가 유효 주소가 된다.
-
-
스택 포인터 레지스터
-
메모리에 프로세서 스택을 구현하는 데 사용한다.
-
많은 프로세서와 주소 레지스터가 데이터 스택 포인터와 규 포인터로 사용된다.
-
보통 반환 주소, 프로세서 상태 정보, 서브 루틴의 임시 변수를 저장한다.
-
3. 사용자가 저장한 정보를 변경할 수 있는지 여부에 따라 분류
가시 레지스터
- 운영체제와 사용자 프로그램을 통해 접근이 가능한 데이터와 주소, 일부 조건 코드를 보관한다.
- 조건코드는 관련된 연산 결과로 발생하며(프로그램적으로 접근하는 제로(0), 자리 넘침, 자리올림, 양수 비트 등이 이에 해당된다.)
사용자 불가시 레지스터
- 프로세스의 제어와 상태를 관리한다.
- 사용자 불가시 레지스터 종류 :
-
프로그램 카운터(PC, Program Counter)
-
프로그램 수행을 제어하는 명령어 실행 순서를 보관한다.
-
즉, 다음에 실행할 명령어의 주소를 저장한다.
-
계수기로 되어 있어 실행할 명령어를 메모리에서 읽으면 프로그램 카운터가 증가한다.
-
-
명령어 레지스터(IR, Instruction Register)
-
현재 수행하는 명령어를 저장한다.
-
명령어의 연산자 부분만 보관하므로 다른 레지스터만큼 비트를 가질 필요는 없다.
-
특히, 메모리 내에서만 전달되므로 메모리 버퍼 레지스터와 명령어 레지스터 사이에 직접 정보 전달 경로를 통해 명령어 연산자를 빠르게 전달할 수 있다.
-
-
프로그램 상태 레지스터(PSR, Program Status Register)
-
플래그 같은 상태 정보를 저장한다.
-
상태 정보에는 플래그 외에도 프로그램 카운터에 저장된 주소 정보 등이 있다.
-
프로그램이 수행되는 순간마다 프로그램의 수행 상태와 프로세서 상태를 나타낸다.
-
-
메모리 주소 레지스터( MAR, Memory Address Register)
-
접근하려는 메모리의 주소를 저장한다.
-
주소 레지스터, 프로그램 카운터 등으로부터 주소 정보를 전달받는다.
-
-
메모리 버퍼 레지스터 (MBR, Memory Buffer Register)
-
메모리에서 정보를 읽을 때 또는 정보를 저장할 때 사용한다.
-
연산장치를 통해 메모리 주소 레지스터, 인덱스 레지스터, 프로그램 카운터 등의 주소 레지스터와 데이터 레지스터에 정보를 전달하는 데 사용한다.
-
이외에도 프로세서에는 다양한 레지스터가 있고, 아래 그림 1-4는 프로세서에 있는 기본 레지스터를 보여준다.
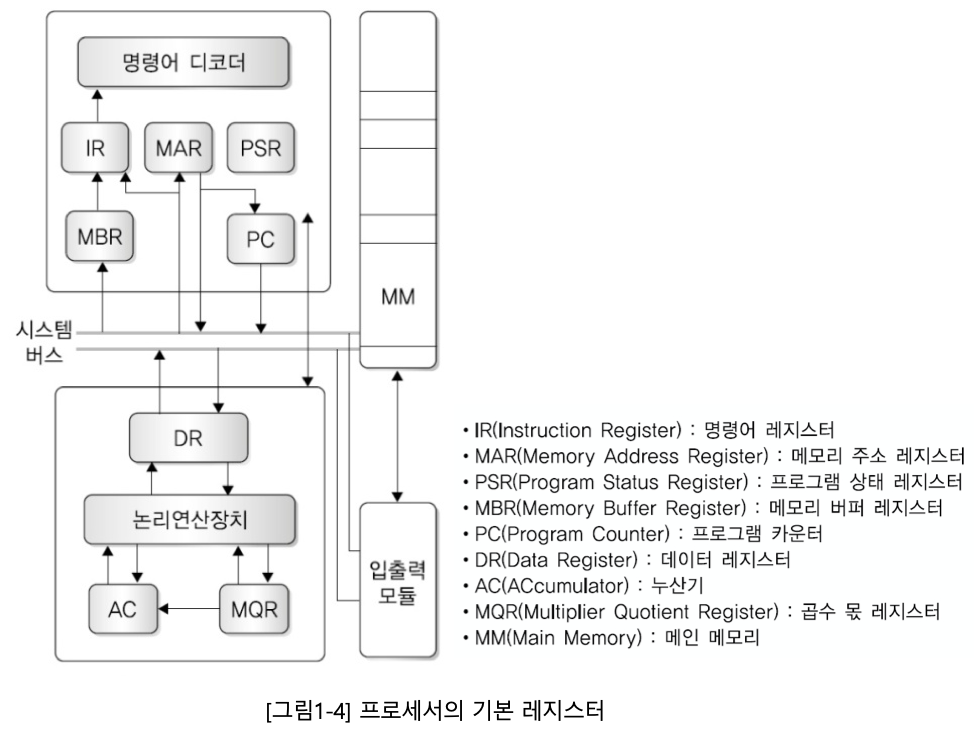
1-4) 메모리

* 메모리 계층 구조는 다양한 레벨의 메모리를 연결하여 비용, 속도, 용량, 접근 시간 등을 상호 보완한 것이다.
-
레지스터 : 프로세서가 사용할 자료를 보관하는 가장 빠른 기억 소자
-
캐시 : 메인 메오리와 프로세서의 속도 차를 보완
-
메인 메모리
-
자기 디스크 : 대용량
-
광학 디스크 : 이동이 편리
-
자기 테이프 : 파일을 저장하기 위한 속도가 느림
- 다양한 메모리를 효과적으로 이용하고 시스템의 성능을 향상하기 위해 사용.
자세히 보려면 더보기 클릭
- 1950년대와 1960년대 메인 메모리가 너무 비싸다는 문제 때문에 제안된 방법.
- 프로그램과 데이터를 실행하고 참조하려면 모두 메인 메모리에 있어야한다.
메모리 계층 구조를 이용하면 즉시 필요하지 않은 프로그램과 데이터를 필요할 때까지 보조기억장치에 저장했다가
실행 참조하려고 할 때 메인 메모리로 옮기면 된다.
- 메모리 계층 구조를 이용할 수 있는 이유는 메모리 참조가 임의로 이루어지는 것이 아니라 지역성(국부성)이라는 특징을 가지기 때문
- 지역성 : 실행 중인 프로세서가 실행기간 동안 메모리 정보를 균일하게 접근하지 않고 블록 중 일부만 집중적으로 참조하는 현상
- 지역성 발생의 이유 :
-
프로그램은 명령어를 순차적으로 실행하는 경향이 있으므로 명령어는 특정 지역 메모리에 인접해 있다.
-
프로그램은 순환의 반복이지만 메모리 참조 영역은 일부 영역에 국한된다.
-
대부분의 컴파일러는 메모리에 인접한 블록, 즉 배열로 저장하므로 프로그램은 배열 원소를 순차적으로 자주 접근하게 되어 지역적인 배열 접근 경향을 보인다.
* 메인 메모리
- 메인 메모리는 고유 주소를 가진 워드나 바이트로 구성된 대규모 배열로 주소를 읽거나 기록함으로써 상호 작용한다.
- 프로세서나 입출력 장치가 데이터를 저장하고 받아오는 작업장 느낌
ex. 프로세서는 메인 메모리로부터 처리할 데이터를 가져오거나 처리한 결과를 메인 메모리에 저장한다.
입출력장치 역시 메인 메모리에서 데이터를 받거나 저장한다.

자세히 보려면 더보기 클릭
- 다수의 셀(Cels)로 구성. 각 셀은 비트들로 구성
- 만약 셀이 K비트면 2^K 값을 저장할 수 있음
- 데이터가 저장될 때 셀 하나에 저장되거나 여러 셀에 나누어 저장됨
- 셀은 주소에 의해 참조된다. (K비트라면 참조 주소 범위는 0~2^K-1이다.)
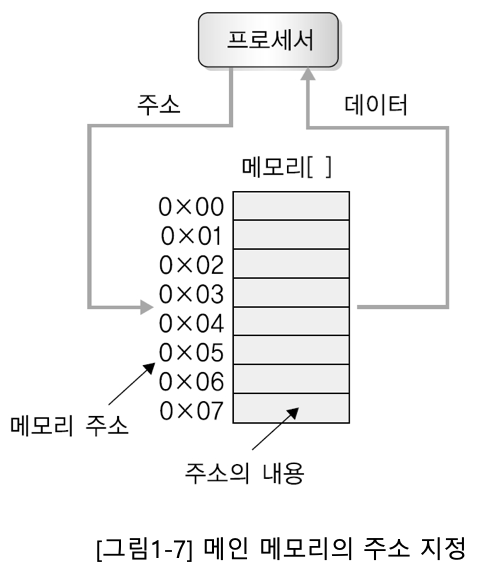
물리적 주소 공간 : 컴퓨터에 주어진 주소 공간
프로그래머는 물리적 주소를 직접 사용하지 않고 수식이나 변수를 사용한다.
그리고 컴파일러가 프로그램을 기계 명령어로 변환할 때 변수와 명령어에 주소를 할당한다.
이 주소를 논리적 주소(가상 주소)라 하고 별도의 주소 공간에 나타난다.
컴파일은 원시 프로그램은 기계 명령어로 변환하는 처리 과정으로, 이 과정에서 컴파일러가 논리적 주소를 물리적 주소로 변환한다.
* 메모리 속도
- 어떤 동작의 시작과 종료 사이의 경과 시간
- 메모리 접근 시간과 메모리 사이클 시간으로 표현
메모리 접근 시간
- 명령 발생 후 목표 번지를 검색하여 데이터 쓰기(읽기)를 시작할 때까지의 시간 (데이터 읽기 쓰기 시작하기 전까지 시간)
ex. 읽기 제어 신호를 가한 후 데이터가 메모리 버퍼 레지스터까지 나오는데 걸리는 시간
메모리 사이클 시간
두 번의 연속적인 메모리 동작 사이에 필요한 최소 지연 시간 (메모리 동작 사이의 쿨타임
ex. 읽기 제어 신호를 가한 후 다음 읽기 제어 신호를 가할 수 있을 때까지의 시간
- 사이클 시간 > 접근시간보다 약간 큼
- 프로세서 - 메모리 - 디스크 사이에서 발생하는 디스크 입출력 병목 현상을 해결하는 역할을 함
- 그런데 프로세서와 메모리 사이의 접근 속도 차가 커짐에 따라 메인 메모리의 부담을 줄이기 위해 칩 안이나 외부에 별도의 캐시를 구현하기도 한다.
* 가상 메모리
- 메인 메모리의 유효 크기를 늘리는 기법
- 디스크 같은 보조기억장치에 프로그램이나 데이터를 저장했다가 필요할 때 다시 메인 메모리로 이동시키는 기술
- 현재 실행 중인 프로그램이나 데이터는 물리적인 메인 메모리 영역에 전부 저장해야 하지만
메인 메모리의 공간 부족으로 다 저장할 수 없다.
이럴 때 가상 메모리를 이용하여 프로그램과 데이터를 보조 기억장치에 일부 저장했다가 필요할 때 다시 메인 메모리로 옮겨 실행하면 효과적이다.
- 이를 위해서 실행 중인 프로세스가 참조하는 주소와 메인 메모리에서 사용하는 주소를 분리해야 한다.
- 현재 진행 중인 프로세스가 참조하는 주소를 논리적 주소(가상 주소, 프로그램 주소)
- 메모리의 실제 주소를 물리적 주소라 한다.
- 논리적 주소를 물리적 주소로 변환하는 과정을 매핑(사상, Mapping) 또는 메모리 맵(Memory Map)이라 한다.
프로그램에 의한 가상 주소 -> 매핑 -> 메인 메모리 실제주소
논리적 주소 물리적 주소
- 가상 메모리는 메인 메모리보다 훨씬 큰 저장 용량의 주소를 지정할 수 있어 프로그램을 부분 적재해 실행할 수 있다.
- 즉, 실제 수행 중인 부분만 실제 메인 메모리로 매핑하고 나머지는 보조기억장치로 매핑한다.
* 캐시
- 처리 속도가 빠른 프로세서와 상대적으로 느린 메인 메모리 사이에서 데이터나 정보를 저장하는 고속 버퍼(둘의 속도차 보완)
- 메모리 가격과 성능을 절충해 느린 메모리 때문에 발생하는 성능 저하를 줄여줌

- 자료 이동
메인 메모리 -> 캐시 : 블록 단위
캐시 -> 프로세서 : 워드 단위
- 자료 조회
캐시에 있으면 이를 사용(캐시 적중)
캐시에 없으면 메인 메모리에서 가져옴(캐시 실패)
- 캐시는 보통 크기가 8~64바이트 정도인 블록 여러 개로 구성.
- 각 블록의 크기는 메인 메모리의 블록 크기와 같다.
캐시의 동작 과정
- 메인 메모리의 주소는 태그(Tag) 영역과 주소 영역 등을 나타내는 연속된 값으로 구성된다.
- 캐시는 메인 메모리 주소 영역을 한 번 읽어 들일 수 있는 라인 크기로 나눈 후 각 블록에 번호를 부여하고 이 번호를 태그로 저장한다.
- 프로세서는 메인 메모리 접근이 필요하면 먼저 캐시를 조사한다.
- 캐시 태그와 메모리 주소의 태그 영역을 비교해 원하는 블록을 찾는다.
ex. 읽기 연산이고 캐시가 데이터를 보관하고 있으면(캐시 태그 = 메모리 주소 태그) 캐시는 데이터 라인에서 요청한 데이터를 읽어 프로세서에 보낸다.
-> 캐시 적중 (Chche Hit)
-> 프로세서가 메인 메모리에서 데이터를 직접 읽어오는 것보다 훨씬 빠르다.
그러나 원하는 주소의 블록이 캐시에 없다면
-> 캐시 실패 (Cache Miss)
캐시 제어기는 메인 메모리에서 해당 블록을 읽어 캐시에 넣고 프로세서에 전송한다.
이때 캐시에는 대응된 주소 태그와 내용이 함께 저장된다.
1-5) 주변 장치
컴퓨터의 기능을 향상하기 위한 추가 장비
ex. 입출력 장치, 보조기억장치, 스캐너, 모뎀 등
2) 컴퓨터 시스템의 동작
2-1) 컴퓨터 시스템의 동작 과정
컴퓨터 시스템은 정보를 디지털 형태로 입력받아 메모리에 저장된 명령어 목록(프로그램)에 따라 처리하고, 결과를 출력하는 일종의 고속 전자계산기다.
보통 아래와 같은 순서로 동작하고 이 모든 동작은 제어장치가 제어한다.
1. 입력장치를 통해 정보를 입력받아 메모리에 저장한다.
2. 메모리에 저장한 정보를 프로그램의 제어에 따라 인출해 산술 장치나 논리 장치에서 처리한다.
3. 처리한 정보를 출력장치에 표시하거나 디스크(보조기억장치)에 저장한다.
정보는 명령어와 데이터로 구분된다.
명령어는 실행할 산술 논리 연산 동작을 명시하는 문장이다.
그리고 어떠한 작업 하나를 수행하기 위한 명령어의 집합을 프로그램이라 한다.
모든 프로그램은 실행 시 메모리에 저장되고, 프로세서는 프로그램을 구성하는 명령어를 메모리에서 한 번에 하나씩 꺼내 원하는 동작을 수행한다.
명령어는 어떻게 구성되고 어 더던 과정을 거쳐 수행되는지 알아보자.
2-2) 명령어의 구성
명령어(Instruction) : 연산 코드 + 오퍼랜드
- 연산 코드(Operation Code) : 프로세서가 실행할 연산을 나타냄
- 오퍼랜드(Operand) : 명령어가 처리할 데이터나 데이터가 저장된 주소(레지스터, 메모리)에 관한 정보를 기술
- 0과 1의 이진 코드화 되어 있음
- 실행 전에 메인 메모리에 순차적으로 저장되고 한 번에 하나씩 프로세서에 전송(fetch)되어 해석(decoding)되고 실행됨(execution)
- 프로세서는 프로그램 카운터(명령어 포인터)를 통해 저장된 명령어를 순차적으로 실행
자세히 보려면 더보기 클릭
명령어
- 명령어 구성, 연산 데이터 종류, 명령어 비트의 할당 상황 등을 나타냄.
- ex. 가감승제, 시프트(shift), 보수 같은 연산을 정의하고 데이터의 위치와 출력 데이터를 지정한다.
- 연산 코드가 n비트라면 최대 2^n가지의 연산이 가능하다.
오퍼랜드
- 연산 대상이 되는 값이나 변수를 지칭하는 말이다.
- 원시 오퍼랜드(Source Operand)와 목적 오퍼랜드(Destination Operand)로 구분한다.
Y = x + b
Y : 목적 오퍼랜드
x, b : 원시 오퍼랜드
+ : 연산 종류(오퍼레이터)
- 연산 종류와 기능에 따라 오퍼랜드 부분을 다양한 용도로 사용할 수 있다.
예를 들어 오퍼랜드 번지 부분이 오퍼랜드의 내용이 담긴 메모리 번지를 가리키면 직접 주소.
오퍼랜드의 내용이 있는 장소의 번지를 저장한 곳을 가리키면 간접 주소라 부른다.
(ex. 100번지에 있는 값이 300이고, 300번지에 실제 피연산자가 들어 있다면, 100이 간접 주소
-> 오퍼랜드의 번지를 읽을 때와 오퍼랜드 자체를 읽을 때 각각 한 번씩, 전체 주 번 메모리를 참조한다.)

2-3) 명령어 실행
-
메모리에서 명령어 레지스터로 이동하여 저장된 다음 명령어를 인출
-
인출한 명령어를 해석하고 다음 명령어를 지정하려고 프로그램 카운터를 변경
-
명령어가 메모리에 있는 워드를 한 개 사용하려면 사용 장소를 결정하여 오퍼랜드를 인출하고 필요하면 프로세서 레지스터로 보냄
-
명령어 실행
-
명령어 실행 결과 저장
-
다음 명령어를 실행하기 위해 1단계로

이 과정은 프로세서의 제어장치가 수행한다.
프로세서는 메모리에서 명령어를 한 번에 한 개씩 인출하고 해석하여 연산한다.
명령어를 인출하여 연산 완료 시점까지를
인출-해석-실행 사이클 = 인출-실행 사이클 = 명령어 실행 사이클이라 한다.
명령어 실행은 인출과 실행 사이클의 반복 처리로 이루어진다.
인출 사이클 -> 간접 사이클 -> 실행 사이클 -> 인터럽트 사이클로 구성된다.
-
인출 사이클 : 메인 메모리에서 명령어를 읽어 명령어 레지스터에 저장
-
간접 사이클 : 명령어에 포함된 주소를 이용해 실제 명령어 실행해 필요한 데이터를 인출
-
실행 사이클 : 해석된 명령어를 실행
-
인터럽트 사이클 : 현재 실행 중인 프로그램 이외의 장치에서 프로세서의 처리가 필요한 상황이 발생한 경우 이를 처리하기 위함
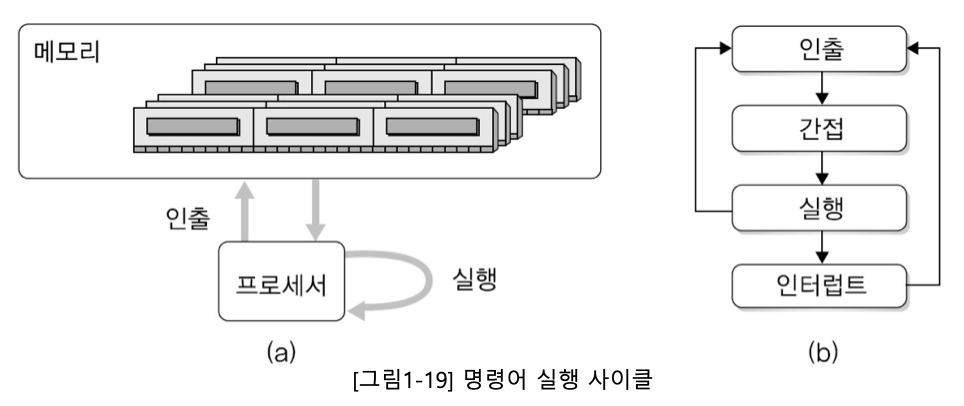
자세히 보려면 더보기 클릭
1. 인출 사이클 - 메인 메모리에서 명령어를 읽어 명령어 레지스터에 저장하기까지의 단계
- 메모리 시스템에서 다음 명령어를 인출하기 위해 필요한 타이밍 신호를 프로세스가 생성한다.
- 이때 명령어는 프로세서 내부에 위치한 명령어 레지스터로 전송된다.
- 여기에 소비되는 시간을 명령어 인출 시간이라 한다.
- 인출 사이클에서 시간에 따른 프로세스 레지스터의 동작

2. 간접 사이클
- 명령어에 포함된 주소를 이용해 실제 명령어 실행에 필요한 데이터를 인출한다.
- 메인 메모리에서 읽은 명령어의 주소가 간접 주소라면 메인 메모리에 다시 접근해 유효 주소를 읽어와야 한다.
-> 인출한 명령어의 주소 필드 내용을 이용해 메모리에서 데이터의 실제 주소를 인출 -> 명령어 레지스터의 주소 필드에 저장한다.
=> 이러한 특성으로 인해 간접 주소 지정 방식에서 사용
- 간접 사이클에서 레지스터 동작 과정

3. 실행 사이클
- 명령어 레지스터의 명령을 해석하고 필요한 신호를 발생시켜 실제로 명령어를 처리한다.
- 소비되는 시간을 실행 시간이라 함.
4. 인터럽트 사이클
- 프로세스가 실행 사이클 후에 종료되지 않고, 프로세서의 정상적인 순차 제어에서 벗어나면 다음과 같은 인터럽트 사이클이 발생한다.
-
프로그램
-
명령어를 실행한 결과로 발생하는 조건에 의해 생성
-
ex. 산술 오버플로우, 0으로 나누기, 범주가 잘못된 명령어로 실행 시도하기 등
-
-
타이머(Timer)
-
프로세서의 타이머에 의해 발생
-
이 경우 운영체제가 특정 함수(기능)를 수행
-
-
입출력(I/O)
-
입출력 제어가 발생시킴
-
연산의 정삭적인 종료를 알리거나 다양한 오류 조건의 신호를 보냄
-
-
하드웨어 오류
-
정전이나 메모리 패리티 오류로 인해 발생
-
- 인터럽트 사이클의 발생 시 레지스터 동작 과정

2-4) 인터럽트
- 컴퓨터에 설정된 장치(입출력 장치, 프로그램 등)에서 프로세서로 보내는 하드웨어 신호
- 현재 실행 중인 프로그램의 수행을 미루고 다른 프로그램의 수행을 요구하는 명령이다.
(인터럽트를 받은 프로그램은 실행을 멈추고 다른 프로그램이 실행됨)
- 인터럽트 사용
-
갑작스러운 정전(H/W)
-
I/O 장치로부터의 처리 요청(H/W)
-
시스템이 예측하지 못한 사용자 입력의 발생(S/W)
-
잘못된 명령어 수행(S/W)
- 장점
-
프로세서가 외부 장치 상태 점검, 이벤트 발생 여부 감시(Polling) 불필요 (입력이 발생했을 때만 프로세서에 통보 및 처리)
-
인터럽트 동안 다른 연산을 수행해 프로세서의 효율을 높일 수 있음
- 구성
-
인터럽트 요청
-
인터럽트 서비스 루틴 (인터럽트 요청 신호에 의해 수행되는 루틴)
- 처리 과정
-
인터럽트 요청 신호 발생 시 실행 중인 프로그램을 메모리에 저장
-
인터럽트 서비스 프로그램(루틴)으로 분기
-
인터럽트 루틴 수행 완료 및 종료
-
인터럽트 발생 전 실행하던 프로그램으로 제어 되돌려 줌
자세히 보려면 더보기 클릭
컴퓨터는 외부 장치의 동작과 자신의 동작을 조정할 수 있는 수단으로 인터럽트를 사용한다.
예를 들어, 다중 사용자 시스템에 키보드를 여러 개 연결하면 각 키보드에서 입력되는 문자를 구분하여 처리해야 한다.
프린터 역시 문자가 출력할 준비가 되어야 컴퓨터가 프린터로 문자를 전송할 수 있다.
따라서 프로세서는 연결된 각 입출력 장치의 현재 상태를 파악하고 있어야 한다.
상태를 나타내기 위해 1비트 이상의 정보로 표현된 준비 비트 또는 상태 비트가 필요하다.
입출력 장치가 새로운 입출력 연산(데이터 전송)을 수행하려고 하면, 프로세서는 먼저 폴링(Polling)을 통해 각 장치의 상태 비트를 검사한다.
인터럽트가 없다면 장치의 상태를 계속 점검하는 과정(Wait Loop)이 필요해 프로세서가 다른 연산을 수행할 수 없으므로 오버헤드가 증가해 수행 시간이 낭비된다.
인터럽트를 사용하면 입력이 발생했을 때만 프로세서에 통보하여 처리하므로 프로세서가 이벤트 발생 여부를 일일이 감시하거나 조사하지 않아도 된다.
입출력 상태가 준비 상태가 될 때까지 프로세서가 다른 작업을 수행할 수 있다.
* 버스 제어선 중 하나를 인터럽트 목적으로 사용하고 이것을 인터럽트 요청 회선(IRQ, Interrupt Request Line)이라 한다.
인터럽트는 크게 인터럽트 요청과 서비스 루틴으로 구선된다.
(인터럽트 서비스 루틴/프로그램(Interrupt Service Routine) : 인터럽트 요청 신호에 의해 수행되는 루틴)
인터럽트 요청 회선을 연결하는 방법에는 단일 회선과 다중 회선이 있다.
단일 회선 : 인터럽트 요청이 가능한 모든 장치를 공통으로 프로세서에 연결하는 방법(어느 장치가 인터럽트를 요청했는지 판별 필요)
다중 회선 : 모든 장치가 서로 다른 고유 회선으로 프로세서에 연결하는 방법(바로 판별 가능)

인터럽트 요청 신호가 발생하면 실행 중인 프로그램을 메모리에 저장하고 인터럽트 서비스 프로그램으로 분기한다.
인터럽트 루틴 수행이 완료되면 인터럽트를 발생시킨 프로그램에 제어를 되돌려 준다.
* 인터럽트 처리 과정
- 현재 (a)에서 프로그램 A가 실행되고 있다.
- PC, 프로그램 카운터는 현재 명령어를 가리킨다.
- (b)에서 인터럽트 신호 발생
- 현재 명령어를 종료하고 스택 영역(프로세스 제어 블록 PCB, Process Control Block)으로 보낸다.
- 인터럽트 처리 프로그램 B의 시작 위치를 PC에 저장하고 B에 제어를 넘기고 실행한다.
- (c)에서 인터럽트 루틴을 종료
- 스택에 있던 내용을 레지스터에 저장하고 중단되었던 PC, A 등이 중단된 지점부터 다시 시작한다.

- 서브 루틴 호출과 매우 유사하지만 차이가 있다.
- 서브 루틴은 자신을 호출한 프로그램이 요구한 기능을 수행
- 인터럽트 서비스 루틴은 인터럽트가 발생했을 때 수행 중인 프로그램과 관련이 없을 수도 있다.
=> 따라서 인터럽트 서비스 루틴 수행 전, 인터럽트가 발생할 때의 상태 코드(워드) 및 수행에 영향을 미치는 정보를 저장해야 함
=> 루틴이 끝나고 복귀후, 임시 기억 장소에 저장한 상태 코드를 다시 적재
=> 이를 통해 프로그램은 인터럽트의 영향을 받지 않고 수행을 재개할 수 있음
요약
* 컴퓨터 시스템 구성
- 컴퓨터는 하나 이상의 프로세서와 메모리, 다양한 입출력 장치로 구성되며 이런 구성요소는 컴퓨터의 주 기능인 프로그램의 실행을 위해 버스로 상호 연결됨
*프로세서
- 컴퓨터 하드웨어 구성요소 중 운영체제와 가장 밀접한 부분으로 컴퓨터 각 부분의 동작을 제어하고 연산을 수행함
- 일반적으로 제어와 데이터의 처리를 담당하며 레지스터로 구성됨
* 버스
- 프로세서를 비롯해 각 장치간 또는 서브 시스템을 서로 연결하여 정보(데이터)를 주고받을 수 있게 해주는 통로
- 위치에 따라 내부 버스와 외부 버스로 구분하며 기능에 따라 데이터 버스, 주소 버스, 제어 버스로 분류
* 레지스터
- 용도에 따라 전담 레지스터와 범용 레지스터로 구분
- 저장되는 정보의 종류에 따라 데이터 레지스터, 주소 레지스터, 상태 레지스터로 구분
- 저장된 정보의 변경 여부에 따라 사용자 가시 레지스터와 사용자 불가시 레지스터로 구분
* 메모리
- 프로그램이 수행되는 동안 프로그램과 데이터가 저장됨
- 사용자와 제조사는 일반적으로 크고 빠르며 비용이 저렴한 메모리를 요구하지만 빠른 장치는 가격이 비싸면서 저장 용량이 적은 단점이 있음
* 메모리 계층 구조
- 여러 레벨의 메모리가 연결되어 비용, 속도, 용량, 접근 시간 등을 상호 보완한 계층적 메모리 구조
*가상 메모리
- 메인 메모리의 유효 크기를 증가시키기 위해 사용하는 기법
- 사용자의 논리적 주소 공간과 컴퓨터희 실제 메모리(물리적 주소 공간)를 분리
- 메인 메모리보다 훨씬 큰 용량의 주소를 지정해 프로그램을 부분 적재하여 실행할 수 있음
* 캐시
- 처리 속도가 빠른 프로세서와 상대적으로 처리 속도가 느린 메인 메모리 사이에서 데이터나 정보를 저장하는 고속 버퍼
- 자주 참조되는 프로그램과 데이터를 속도가 빠른 캐시 메모리에 저장하여 평균 접근 시간을 줄이고 시스템 성능을 향상함
* 명령어
- 사용자가 원하는 연산과 오퍼랜드, 처리 순서를 프로세서에 지시하는 명령문으로 메모리에 보관되며 한 번에 한 개씩 프로세서로 전송되면서 해석되고 실행됨
- 명령어 실행은 명령어 인출과 명령어 실행 주기의 반복
- 명령어 실행 사이클은 인출 사이클, 간접 사이클, 실행 사이클, 인터럽트 사이클로 구성됨
* 인터럽트
- 현재 실행 중인 프로그램의 수행을 연기하고 다른 프로그램의 수행을 요구하는 명령
- 시스템의 처리 효율을 향상하기 위해 사용
- 프로그램이 실행 순서를 바꿔가면서 처리되기 때문에 다중 프로그래밍에 사용
참고
아래를 참고해 정리한 내용입니다.
그림으로 배우는 원리와 구조 - 운영체제(개정판) - 한빛 아카데미
댓글