[Java] 트리 Tree 3 - 이진 탐색 트리
이진 탐색 트리 (Binary Search Tree)
이진 탐색 트리란 이진 탐색 트리의 성질을 만족하는 이진트리
이진트리 기반의 탐색을 위한 자료 구조
이진 탐색 트리의 성질
- 모든 원소의 키는 유일한 키를 가진다.
- 왼쪽 서브 트리 키들은 루트 키보다 작다.
- 오른쪽 서브 트리 키들은 루트 키보다 크다.
- 왼쪽과 오른쪽 서브 트리도 이진 탐색 트리이다.

찾고자 하는 키 값이 이진트리의 루트 노드의 킷값과 비교해
루트 노드보다 작으면 원하는 키값은 왼쪽 서브 트리에 있고,
루트 노드보다 크면 원하는 키 값은 오른쪽 서브 트리에 있다.
ex. 왼쪽 서브 트리의 값들 (3, 7, 12)는 루트 노드인 18보다 작다.
오른쪽 서브 트리의 값들 (26, 31, 27)은 루트 노드인 18보다 크다.
위의 이진 탐색 트리를 중위 순회하면 3, 7, 12, 18, 26, 27, 31로 숫자들의 크기 순이 됨 -> 어느 정도 정렬된 상태
순환적인 탐색 연산
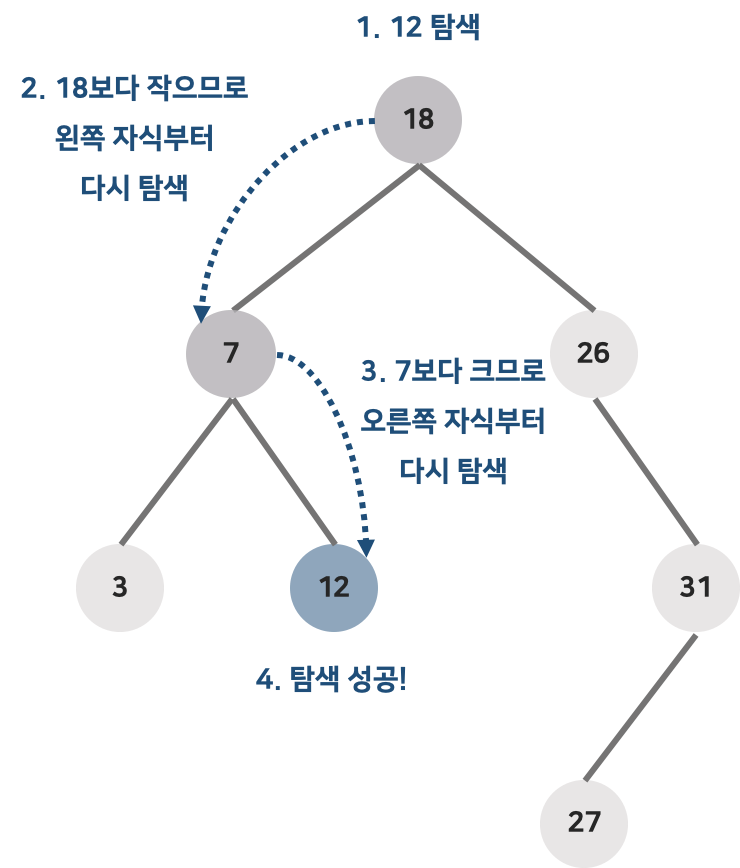
이진 탐색 트리에서 특정한 키값을 가진 노드를 찾기 위해서는 먼저 주어진 탐색키 값과 루트 노드의 키값을 비교한다.
비교한 결과에 따라 3가지로 나누어진다.
- 비교한 결과가 같으면 탐색이 성공적으로 끝난다.
- 비교한 결과가, 주어진 키 값이 루트 노드의 키값보다 작으면, 탐색은 이 루트 노드의 왼쪽 자식을 기준으로 다시 시작한다.
- 비교한 결과가, 주어진 키 값이 루트 노드의 키값보다 크면, 탐색은 이 루트 노드의 오른쪽 자식을 기준으로 다시 시작한다.
- 탐색키 값 == 루트 노드의 키 값 : 탐색 완료
- 탐색키 값 < 루트 노드의 키 값 : 루트 노드의 왼쪽 자식 노드를 기준으로 재탐색
- 탐색키 값 > 루트 노드의 키 값 : 루트 노드의 오른쪽 자식 노드를 기준으로 재탐색
// 순환적인 탐색
public static Node circularSearch(Node node, int key) {
if(node == null) {
return null;
}
if(key == node.data) {
return node;
} else if(key < node.data) {
return circularSearch(node.left, key);
} else {
return circularSearch(node.right, key);
}
}
반복적인 탐색 연산
while문을 이용해 반복적인 기법으로 탐색 연산을 구현한 것이다.
매개변수 node가 null이 아니면 반복을 계속한다.
반복 루프 안에서는 현재 node의 data값이 key값과 같은지 검사한다.
-
같으면 탐색 성공으로 현재 노드를 반환하고 끝
-
key가 현재 노드값보다 작으면 node 변수를 node의 왼쪽 자식 노드를 가리키도록 변경
-
key값이 현재 노드의 값보다 크면 node 변수를 node의 오른쪽 자식을 가리키도록 변경
node가 단말 노드까지 내려가서 null 값이 될 때까지 반복
만약 반복이 종료되었는데도 아직 함수가 리턴되지 않았다면 탐색이 실패한 것으로 null 반환
// 반복적인 탐색
public static Node repetitiveSearch(Node node, int key) {
while(node != null) {
if(key == node.data) {
return node;
} else if(key < node.data) {
node = node.left;
} else {
node = node.right;
}
}
return null; // 탐색 실패했을 경우
}
이진 탐색 트리에서의 삽입 연산
원소를 삽입하기 위해서는 먼저 탐색을 수행해야 한다.
이진 탐색 트리에서는 같은 키값을 갖는 노드가 없어야 하고, 탐색에 실패한 위치가 바로 새로운 노드를 삽입하는 위치가 되기 때문이다.

ex) 9를 삽입하는 경우
1과 같이 루트에서 부터 9를 탐색한다.
만약 탐색이 성공하면 이미 9가 트리 안에 존재 -> 중복 -> 삽입 불가
만약 9트리 안에 없다면 -> 탐색 실패 -> 실패한 위치가 9가 삽입될 곳
따라서 탐색 실패 위치인 12의 왼쪽에 9를 삽입한다.
새로운 노드는 항상 단말 노드에 추가된다.
단말 노드를 발견할 때까지 루트에서 key를 검색한다.
단말 노드가 발견되면 새로운 노드가 단말 노드의 하위 노드로 추가된다.
// 노드 삽입
public Node insertNode(Node node, int key) {
if(node == null) {
return new Node(key); // 노드가 빈 경우, 새로운 노드 삽입후 반환
}
// 그렇지 않으면 순환적으로 트리를 내려감
if(key < node.data) {
node.left = insertNode(node.left, key);
} else if(key > node.data) {
node.right = insertNode(node.right, key);
}
// 삽입 완료 후, 루트 노드 반환하며 끝
return node;
}
이진 탐색 트리에서의 삭제 연산
이진 탐색 트리에서 가장 복잡한 연산이다.
삭제하기 위해서 먼저 노드를 탐색해야 한다.
탐색 후에는 3가지 경우를 고려해야 한다.
-
삭제하려는 노드가 단말 노드일 경우
-
삭제하려는 노드가 하나의 서브 트리만(왼쪽 or 오른쪽) 가지고 있는 경우
-
삭제하려는 노드가 두 개의 서브 트리를 가지고 있는 경우
1. 삭제하려는 노드가 단말 노드일 경우
단말 노드 아래에는 더 이상의 노드가 없으므로 단말 노드만 지우면 된다.
단말 노드의 부모 노드를 찾아서 부모 노드의 링크 필드를 null로 만들어 연결을 끊는다.

2. 삭제하려는 노드가 하나의 서브 트리만 가지고 있는 경우
자기 노드는 삭제하고, 서브 트리는 자기 노드의 부모 노드에 붙여주면 된다.
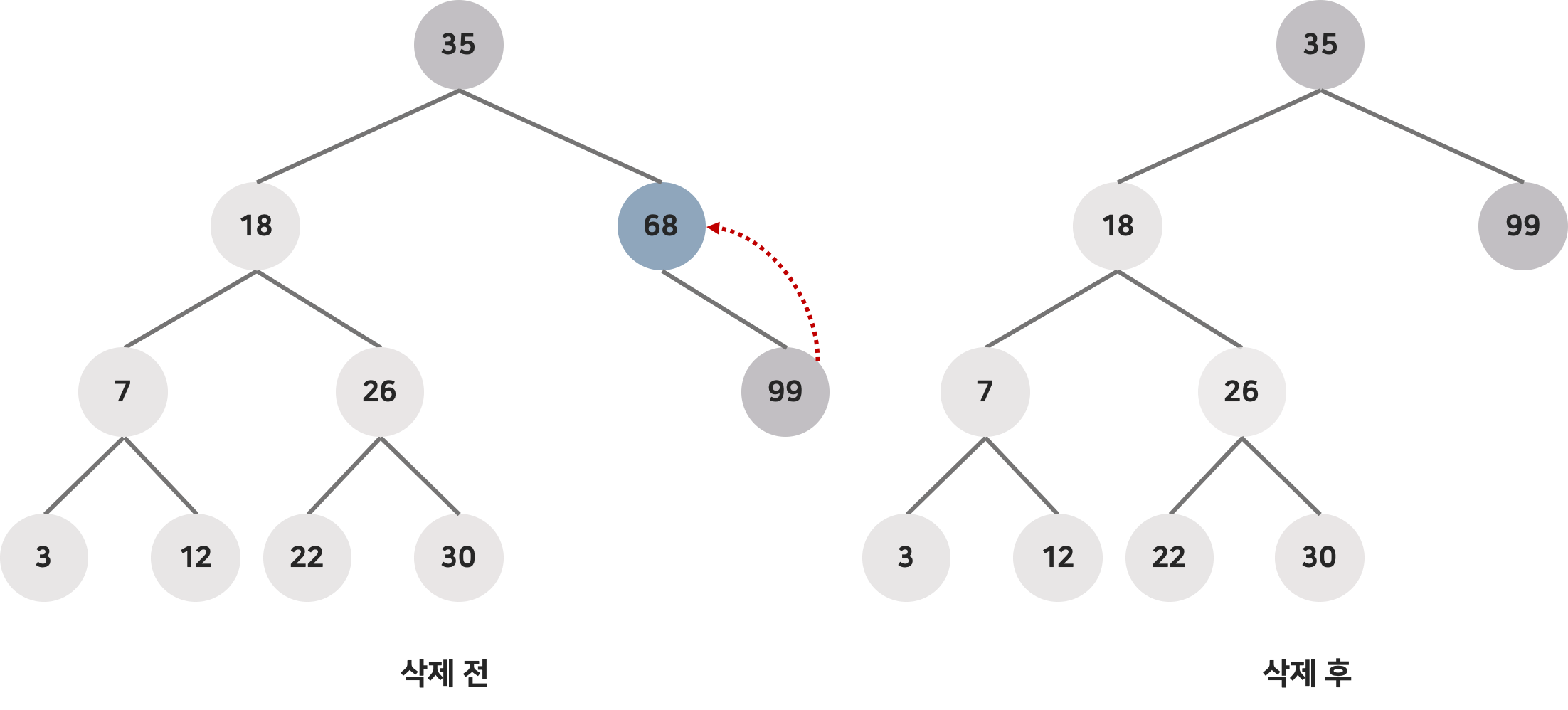
3. 삭제하려는 노드가 두 개의 서브 트리를 가지고 있는 경우
어떤 노드를 삭제 노드 위치로 가져올 것이냐가 중요하다.
삭제되는 노드와 가장 값이 비슷한 노드를 후계자로 선택해야 이진 탐색 트리가 그대로 유지된다.
그렇다면 가장 값이 가까운 노드란?
왼쪽 서브 트리에서 가장 큰 값이나 오른쪽 서브트리에서 가장 작은 값이 삭제되는 노드와 가장 가깝다.
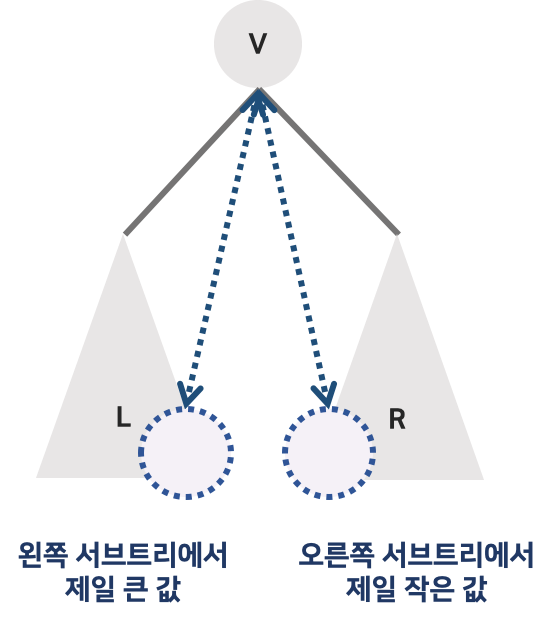
-
왼쪽 서브 트리의 가장 큰 값 - 왼쪽 서브트리에서 가장 오른쪽에 있는 노드
-
오른쪽 서브트리에서 가장 작은 값 - 오른쪽 서브트리의 가장 왼쪽에 있는 노드
이 두 노드는 이진 탐색 트리를 중위 순회하였을 경우, 각각 선행 노드와 후속 노드에 해당한다.
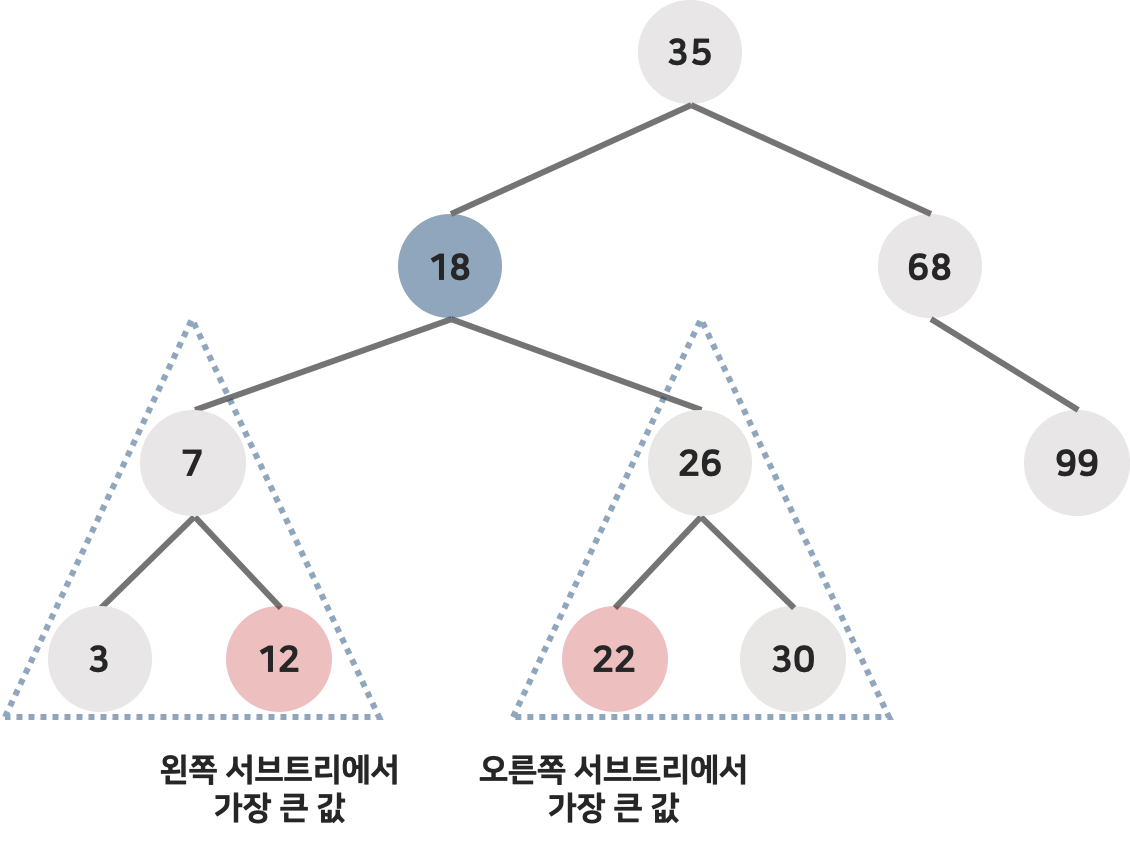
예를 들어 삭제 노드가 18일 경우, 후계자가 될 수 있는 노드는 12와 22가 된다.
18 자리로 두 노드를 옮겨도 아무런 문제가 일어나지 않음
이 두 후계자 중에서 어떤 노드를 선택해야 할까?
상관없다. 지금은 오른쪽 서브 트리에서 가장 작은 값을 후계자로 정해보자.

삭제되는 노드의 오른쪽 서브 트리에서 가장 작은 값을 갖는 노드는
오른쪽 서브트리에서 왼쪽 자식 노드를 타고 null을 만날 때까지 계속 타고 내려가면 찾을 수 있다.

최종적으로 22가 후계자가 되고, 22가 18의 자리로 이동된다.
// 노드 삭제
public Node deleteNode(Node root, int key) {
if(root == null) {
return root;
}
if(key < root.data) { // 키가 루트보다 작다면, 왼쪽 서브 트리에 있는 것
root.left = deleteNode(root.left, key);
} else if(key > root.data) { // 키가 루트보다 크다면, 오른쪽 서브 트리에 있는 것
root.right = deleteNode(root.right, key);
} else { // 키가 루트와 같다면 이 노드가 바로 삭제할 노드
if(root.left == null) { // 1번, 2번의 경우 - 1. 단말 노드인 경우 / 2. 하나의 서브트리만 있는 경우
return root.right; // 널 값이면 널 반환 / 오른쪽 있으면 오른쪽 반환해서 이전의 if, else if에서의 왼쪽이든 오른쪽 노드에 붙여주는 것
} else if(root.right == null) {
return root.left; // left가 널인 경우와 동일
}
// 3번의 경우 - 3. 두개의 서브 트리가 있는 경우 (left, right 둘 다 null 아님
Node temp = minValueNode(root.right); // 오른쪽 서브 트리에서 가장 작은 값(가장 왼쪽 노드)가 후계 노드
root.data = temp.data; // 후계 노드 값 복사(삭제할 노드의 값을 후계 노드 값으로 변경
root.right = deleteNode(root.right, temp.data); // 후계 노드 삭제 - 오른쪽 노드에게 가장 작은 값을 가졌던 맨 왼쪽 단말노드를 다시 deleteNode를 호출해 삭제하라고 함
}
return root;
}
// 후계 노드 찾기 - 오른쪽 서브트리에서 가장 작은 값을 가지는 노드 반환
public Node minValueNode(Node node) {
Node currentNode = node;
while(currentNode.left != null) {
currentNode = currentNode.left; // 맨 왼쪽 단말 노드를 찾으러 내려감
}
return currentNode;
}
전체 코드
import java.util.Scanner;
public class BinarySearchTree {
class Node {
int data;
Node left;
Node right;
Node(int data){
this.data = data;
}
}
public Node root;
// 순환적인 탐색
public static Node circularSearch(Node node, int key) {
if(node == null) {
return null;
}
if(key == node.data) {
return node;
} else if(key < node.data) {
return circularSearch(node.left, key);
} else {
return circularSearch(node.right, key);
}
}
// 반복적인 탐색
public static Node repetitiveSearch(Node node, int key) {
while(node != null) {
if(key == node.data) {
return node;
} else if(key < node.data) {
node = node.left;
} else {
node = node.right;
}
}
return null; // 탐색 실패했을 경우
}
// 노드 삽입
public Node insertNode(Node node, int key) {
if(node == null) {
return new Node(key); // 노드가 빈 경우, 새로운 노드 삽입후 반환
}
// 그렇지 않으면 순환적으로 트리를 내려감
if(key < node.data) {
node.left = insertNode(node.left, key);
} else if(key > node.data) {
node.right = insertNode(node.right, key);
}
// 삽입 완료 후, 루트 노드 반환하며 끝
return node;
}
// 노드 삭제
public Node deleteNode(Node root, int key) {
if(root == null) {
return root;
}
if(key < root.data) { // 키가 루트보다 작다면, 왼쪽 서브 트리에 있는 것
root.left = deleteNode(root.left, key);
} else if(key > root.data) { // 키가 루트보다 크다면, 오른쪽 서브 트리에 있는 것
root.right = deleteNode(root.right, key);
} else { // 키가 루트와 같다면 이 노드가 바로 삭제할 노드
// 1번, 2번의 경우
if(root.left == null) {
return root.right;
} else if(root.right == null) {
return root.left;
}
// 3번의 경우
Node temp = minValueNode(root.right); // 후계 노드 찾기
root.data = temp.data; // 후계 노드 값 복사
root.right = deleteNode(root.right, temp.data); // 후계 노드 삭제
}
return root;
}
// 후계 노드 찾기 - 오른쪽 서브트리에서 가장 작은 값을 가지는 노드 반환
public Node minValueNode(Node node) {
Node currentNode = node;
while(currentNode.left != null) {
currentNode = currentNode.left; // 맨 왼쪽 단말 노드를 찾으러 내려감
}
return currentNode;
}
// 중위 순회
public void inOrder(Node node) {
if(node != null) {
if(node.left != null) inOrder(node.left);
System.out.print(node.data + " ");
if(node.right != null) inOrder(node.right);
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
BinarySearchTree t = new BinarySearchTree();
for (int i = 0; i < n; i++) {
int key = sc.nextInt();
if(circularSearch(t.root, key) == null) {
t.root = t.insertNode(t.root, key);
}
}
System.out.println("\n이진 탐색 트리 중위 순회");
t.inOrder(t.root);
if(repetitiveSearch(t.root, 68) != null) {
System.out.println("\n\n68 탐색 성공");
} else {
System.out.println("\n\n68 탐색 실패");
}
System.out.println("\n1. 단말 노드 삭제 - 30 삭제 ");
t.deleteNode(t.root, 30);
t.inOrder(t.root);
System.out.println("\n\n2. 하나의 서브트리만 가진 노드 삭제 - 68 삭제 ");
t.deleteNode(t.root, 68);
t.inOrder(t.root);
System.out.println("\n\n3. 두개의 서브트리를 가진 노드 삭제 - 18 삭제 ");
t.deleteNode(t.root, 18);
t.inOrder(t.root);
}
}입력
첫 번째 줄에 트리의 노드 개수 n이 주어진다. ( 1 ≤ n ≤ 100 )
두 번째 줄에 루트 노드의 값이 주어진다.
세 번째 줄부터 n-1까지의 노드 값이 주어진다.
(노드를 막 삽입하다보면 편향트리가 만들어져서 원하는 탐색, 삽입, 삭제 구현이 안됨.
따라서 루트 노드를 먼저 삽입 후 레벨별로 왼쪽에서 오른쪽 순서로 노드를 삽입합)
10
35
18
68
7
26
99
3
12
22
30출력
이진 탐색 트리 중위 순회
3 7 12 18 22 26 30 35 68 99
68 탐색 성공
1. 단말 노드 삭제 - 30 삭제
3 7 12 18 22 26 35 68 99
2. 하나의 서브트리만 가진 노드 삭제 - 68 삭제
3 7 12 18 22 26 35 99
3. 두개의 서브트리를 가진 노드 삭제 - 18 삭제
3 7 12 22 26 35 99
이진 탐색 트리의 분석
이진 탐색 트리에서의 탐색, 삽입, 삭제 연산의 시간 복잡도는 트리의 높이를 h라고 했을 때 O(h)가 된다.
따라서 n개의 노드를 가지는 이진 탐색 트리의 경우, 일반적인 이진트리의 높이는 O(log2n)이므로
이진 탐색 트리 연산의 평균적인 경우의 시간 복잡도는 O(log 2 h)이다.
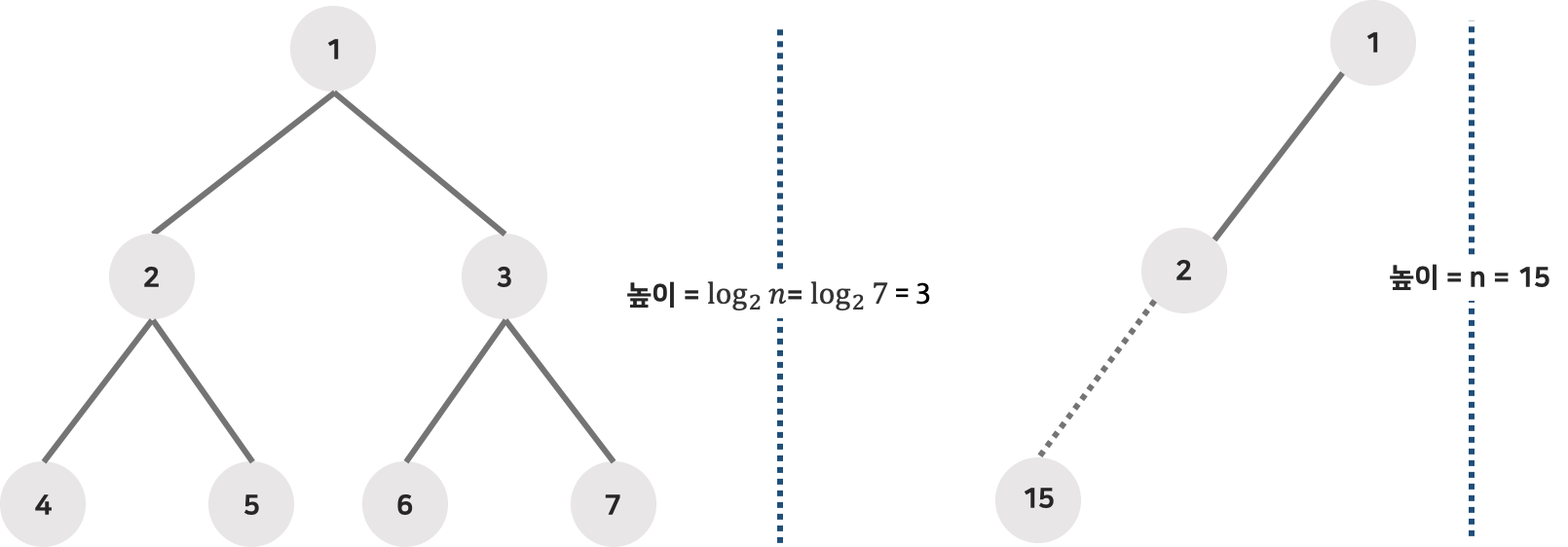
좌우의 서브 트리가 균형을 이룰 경우가 아닌,
최악의 경우에는 한쪽으로 치우치는 경사 트리가 되어 트리의 높이가 n이 된다.
이 경우에는 거의 선형 탐색과 같이 O(n)이 된다.
따라서 이러한 최악의 경우를 방지하기 위해 트리의 높이를 [log 2 n]으로 한정시키는 균형 기법이 필요하다. (ex. AVL 트리 등)
[C & Java] 트리 Tree 1 - 트리? / 이진트리? / 트리 표현법
[Java] 트리(tree) 구현 - 1차원 배열 / 2차원 배열 / 클래스 3가지 방법 구현
[Java] 트리 Tree 2 - 이진트리의 순회(전위, 중위, 후위, 반복, 레벨) / 구현
[Java] 트리 Tree 3 - 이진 탐색 트리
관련 포스트
[C & Java] 트리 Tree 1 - 트리? / 이진트리? / 트리 표현법
[Java] 트리(tree) 구현 - 1차원 배열 / 2차원 배열 / 클래스 3가지 방법 구현
[Java] 트리 Tree 2 - 이진트리의 순회(전위, 중위, 후위, 반복, 레벨) / 구현
[Java] 트리 Tree 3 - 이진 탐색 트리
참고
C언어로 쉽게 풀어쓴 자료구조(개정 3판) - 생능 출판